
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License
About this document¶
This document was created using Weave.jl. The code is available on github. The same document generates both the static webpage and associated jupyter notebook (or on nbviewer).
Optimization Algorithms¶
The goal of this notebook is to give you some familiarity with numeric optimization.
Numeric optimization is important because many (most) models cannot be fully solved analytically. Numeric results can be used to complement analytic ones. Numeric optimization plays a huge role in econometrics.
In these notes, we will focus on minimization problems following the convention in mathematics, engineering, and most numerical libraries. It is easy to convert between minimization and maximization, and we hope that this does not lead to any confusion.
Heuristic searches¶
The simplest type of optimization algorithm are heuristic searches. Consider the problem:
with $f:\R^n \to \R$. Heuristic search algorithms consist of
- Evaluate $f$ at a collection of points
- Generate a new candidate point, $x^{new}$. Replace a point in the current collection with $x^{new}$ if $f(x^{new})$ is small enough.
- Stop when function value stops decreasing and/or collection of points become too close together.
There are many variants of such algorithms with different ways of generating new points, deciding whether to accept the new point, and deciding when to stop. Here is a simple implementation and animation of the above idea. In the code below, new points are drawn randomly from a normal distribution, and new points are accepted whenever $f(x^{new})$ is smaller than the worst existing function value.
markdown && printfunc("minrandomsearch","heuristic_optimizers.jl")
"""
minrandomsearch(f, x0, npoints; var0=1.0, ftol = 1e-6,
vtol = 1e-4, maxiter = 1000,
vshrink=0.9, xrange=[-2., 3.],
yrange=[-2.,6.])
Find the minimum of function `f` by random search.
Creates an animation illustrating search progress.
# Arguments
- `f` function to minimize
- `x0` starting value
- `npoints` number of points in cloud
- `var0` initial variance of points
- `ftol` convergence tolerance for function value. Search terminates if bot
h function change is less than ftol and variance is less than vtol.
- `vtol` convergence tolerance for variance. Search terminates if both func
tion change is less than ftol and variance is less than vtol.
- `maxiter` maximum number of iterations
- `vshrink` after every 100 iterations with no function improvement, the va
riance is reduced by this factor
- `xrange` range of x-axis in animation
- `yrange` range of y-axis in animation
- `animate` whether to create animation
# Returns
- `(fmin, xmin, iter, info, anim)` tuple consisting of minimal function
value, minimizer, number of iterations, convergence info, and an animatio
n
"""
function minrandomsearch(f, x0, npoints; var0=1.0, ftol = 1e-6,
vtol = 1e-4, maxiter = 1000,
vshrink=0.9, xrange=[-2., 3.],
yrange=[-2.,6.], animate=true)
var = var0 # current variance for search
oldbest = Inf # smallest function value
xbest = x0 # x with smallest function vale
newbest = f(xbest)
iter = 0 # number of iterations
noimprove = 0 # number of iterations with no improvement
animate = (animate && length(x0)==2)
if animate
# make a contour plot of the function we're minimizing. This is for
# illustrating; you wouldn't have this normally
x = range(xrange[1],xrange[2], length=100)
y = range(yrange[1],yrange[2], length=100)
c = contour(x,y,(x,y) -> log(f([x,y])))
anim = Animation()
else
anim = nothing
end
while ((oldbest - newbest > ftol || var > vtol) && iter<=maxiter)
oldbest = newbest
x = rand(MvNormal(xbest, var),npoints)
if animate
# plot the search points
p = deepcopy(c)
scatter!(p, x[1,:], x[2,:], markercolor=:black, markeralpha=0.5, lege
nd=false, xlims=xrange, ylims=yrange)
end
fval = mapslices(f,x, dims=[1])
(newbest, i) = findmin(fval)
if (newbest > oldbest)
noimprove+=1
newbest=oldbest
else
xbest = x[:,i[2]]
noimprove = 0
end
if animate
# plot the best point so far
scatter!(p, [xbest[1]],[xbest[2]], markercolor=:red, legend=false)
end
if (noimprove > 10) # shrink var
var *= vshrink
end
if animate
frame(anim) # add frame to animation
end
iter += 1
end
if (iter>maxiter)
info = "Maximum iterations reached"
else
info = "Convergence."
end
return(minimum = newbest, minimizer = xbest, iters = iter, info = info, a
nim = anim)
end
"""
banana(a,b)
Returns the Rosenbrock function with parameters a, b.
"""
function banana(a,b)
x->(a-x[1])^2+b*(x[2]-x[1]^2)^2
end
f = banana(1.0,1.0)
x0 = [-2.0, 3.0];
result = minrandomsearch(f, x0, 20, var0=0.1, vshrink=0.5, vtol=1e-3 )
gif(result[5], "randsearch.gif", fps=5);
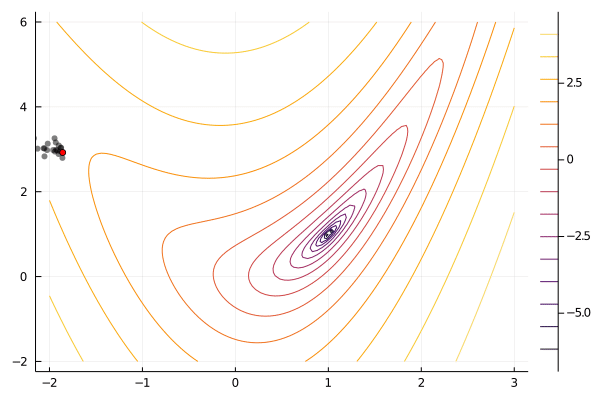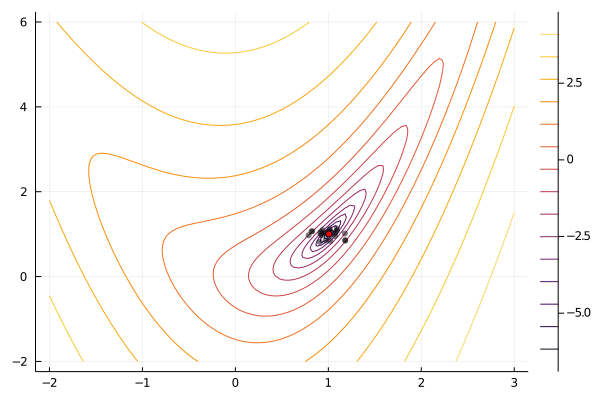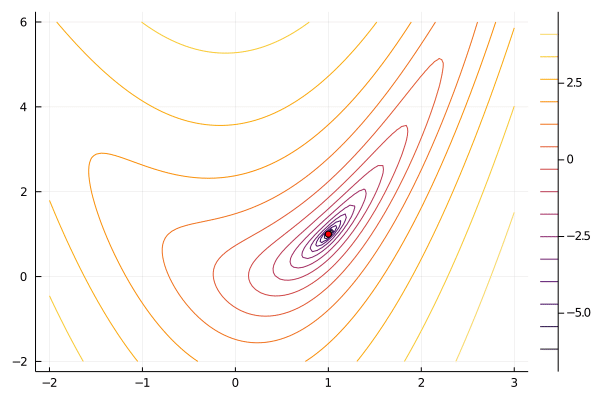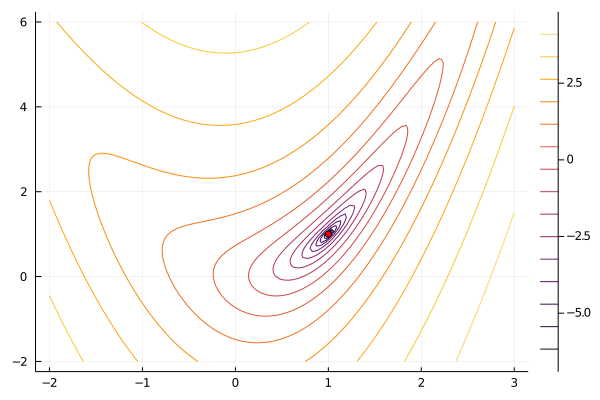
There are many other heuristic search algorithms. A popular deterministic one is the Nelder-Mead simplex. Popular heuristic search algorithms that include some randomness include simulated annealing and particle swarm. Each of the three algorithms just mentioned are available in Optim.jl. These heuristic searches have the advantage that they only function values (as opposed to also requiring gradients or hessians, see below). Some heuristic algorithms, like simulated annealing, can be shown to converge to a global (instead of local) minimum under appropriate assumptions. Compared to algorithms that use more information, heuristic algorithms tend to require many more function evaluations.
Gradient descent¶
Gradient descent is an iterative algorithm to find a local minimum. As the name suggests, it consists of descending toward a minimum in the direction opposite the gradient. Each step, you start at some $x$ and compute $x_{new}$
- Given current $x$, compute $x_{new} = x - \gamma Df_{x}$
- Adjust $\gamma$ depending on whether $f(x_{new})<f(x)$
- Repeat until $\norm{Df_{x}}$, $\norm{x-x_{new}}$, and/or $\abs{f(x)-f(x_{new})}$ small.
using ForwardDiff, LinearAlgebra
markdown && printfunc("graddescent","smooth_optimizers.jl")
"""
graddescent(f, x0; grad=x->Forwardiff.gradient(f,x),
γ0=1.0, ftol = 1e-6,
xtol = 1e-4, gtol=1-6, maxiter = 1000,
xrange=[-2., 3.],
yrange=[-2.,6.], animate=true)
Find the minimum of function `f` by gradient descent
# Arguments
- `f` function to minimize
- `x0` starting value
- `grad` function that computes gradient of `f`
- `γ0` initial step size multiplier
- `ftol` tolerance for function value
- `xtol` tolerance for x
- `gtol` tolerance for gradient. Convergence requires meeting all three tol
erances.
- `maxiter` maximum iterations
- `xrange` x-axis range for animation
- `yrange` y-axis range for animation
- `animate` whether to create animation
# Returns
- `(fmin, xmin, iter, info, anim)` tuple consisting of minimal function
value, minimizer, number of iterations, convergence info, and animations
"""
function graddescent(f, x0; grad=x->ForwardDiff.gradient(f,x),
γ0=1.0, ftol = 1e-6,
xtol = 1e-4, gtol=1-6, maxiter = 1000,
xrange=[-2., 3.],
yrange=[-2.,6.], animate=true)
fold = f(x0)
xold = x0
xchange=Inf
fchange=Inf
γ = γ0
iter = 0
stuck=0
improve = 0 # we increase γ if 5 steps in a row improve f(x)
animate = animate && (length(x0)==2)
if animate
# make a contour plot of the function we're minimizing. This is for
# illustrating; you wouldn't have this normally
c = contour(range(xrange[1],xrange[2], length=100),
range(yrange[1],yrange[2], length=100),
(x,y) -> log(f([x,y])))
anim = Animation()
else
anim = nothing
end
g = grad(xold)
while(iter < maxiter && ((xchange>xtol) || (fchange>ftol) || (stuck>0)
|| norm(g)>gtol) )
g = grad(xold)
x = xold - γ*g
fnew = f(x)
if animate
scatter!(c, [xold[1]],[xold[2]], markercolor=:red, legend=false,
xlims=xrange, ylims=yrange)
quiver!(c, [xold[1]],[xold[2]], quiver=([-γ*g[1]],[-γ*g[2]]), legend=
false,
xlims=xrange, ylims=yrange)
frame(anim)
end
if (fnew>=fold)
γ*=0.5
improve = 0
stuck += 1
if (stuck>=10)
break
end
else
stuck = 0
improve += 1
if (improve>5)
γ *= 2.0
improve=0
end
xold = x
fold = fnew
end
xchange = norm(x-xold)
fchange = abs(fnew-fold)
iter += 1
end
if (iter >= maxiter)
info = "Maximum iterations reached"
elseif (stuck>0)
info = "Failed to improve for " * string(stuck) * " iterations."
else
info = "Convergence."
end
return(fold, xold, iter, info, anim)
end
result = graddescent(f, x0)
gif(result[5], "graddescent.gif", fps=10);
Although an appealing and intuitive idea, the above example
illustrates that gradient descent can perform surprisingly poorly in
some cases. Nonetheless, gradient descent is useful for some
problems. Notably, (stochastic) gradient descent is used to fit neural
networks, where the dimension of x is so large that computing the
inverse hessian in (quasi) Newton’s method is prohibitively time
consuming.
Newton’s method¶
Newton’s method and its variations are often the most efficient minimization algorithms. Newton’s method updates $x$ by minimizing a second order approximation to $f$. Specifically:
- Given $x$ set $x_{new} = x - (D^2f_x)^{-1} Df_x$
- Repeat until $\norm{Df_{x}}$, $\norm{x-x_{new}}$, and/or $\abs{f(x)-f(x_{new})}$ small.
markdown && printfunc("newton","smooth_optimizers.jl")
"""
newton(f, x0;
grad=x->ForwardDiff.gradient(f,x),
hess=x->ForwardDiff.hessian(f,x),
ftol = 1e-6,
xtol = 1e-4, gtol=1-6, maxiter = 1000,
xrange=[-2., 3.],
yrange=[-2.,6.], animate=true)
Find the minimum of function `f` by Newton's method.
# Arguments
- `f` function to minimizie
- `x0` starting value
- `grad` function that returns gradient of `f`
- `hess` function that returns hessian of `f`
- `ftol` tolerance for function value
- `xtol` tolerance for x
- `gtol` tolerance for gradient. Convergence requires meeting all three tol
erances.
- `maxiter` maximum iterations
- `xrange` x-axis range for animation
- `yrange` y-axis range for animation
- `animate` whether to create animation
# Returns
- `(fmin, xmin, iter, info, anim)` tuple consisting of minimal function
value, minimizer, number of iterations, convergence info, and animation
"""
function newton(f, x0;
grad=x->ForwardDiff.gradient(f,x),
hess=x->ForwardDiff.hessian(f,x),
ftol = 1e-6,
xtol = 1e-4, gtol=1-6, maxiter = 1000,
xrange=[-2., 3.],
yrange=[-2.,6.], animate=true)
fold = f(x0)
xold = x0
xchange=Inf
fchange=Inf
iter = 0
stuck=0
animate=animate && length(x0)==2
if animate
# make a contour plot of the function we're minimizing. This is for
# illustrating; you wouldn't have this normally
c = contour(range(xrange[1],xrange[2], length=100),
range(yrange[1],yrange[2], length=100),
(x,y) -> log(f([x,y])))
anim = Animation()
end
g = grad(xold)
while(iter < maxiter && ((xchange>xtol) || (fchange>ftol) || (stuck>0)
|| norm(g)>gtol) )
g = grad(xold)
H = hess(xold)
Δx = - inv(H)*g
x = xold + Δx
fnew = f(x)
step = 1.0
while (fnew>=fold && step>xtol)
step /= 1.618
x = xold + Δx*step
fnew = f(x)
end
if animate
scatter!(c, [xold[1]],[xold[2]], markercolor=:red, legend=false,
xlims=xrange, ylims=yrange)
quiver!(c, [xold[1]],[xold[2]], quiver=([Δx[1]],[Δx[2]]), legend=fals
e,
xlims=xrange, ylims=yrange)
frame(anim)
end
if (fnew>=fold)
stuck += 1
if (stuck>=10)
break
end
else
stuck = 0
xold = x
fold = fnew
end
xchange = norm(x-xold)
fchange = abs(fnew-fold)
iter += 1
end
if (iter >= maxiter)
info = "Maximum iterations reached"
elseif (stuck>0)
info = "Failed to improve for " * string(stuck) * " iterations."
else
info = "Convergence."
end
return(fold, xold, iter, info, anim)
end
result = newton(f, x0)
gif(result[5], "newton.gif", fps=5);
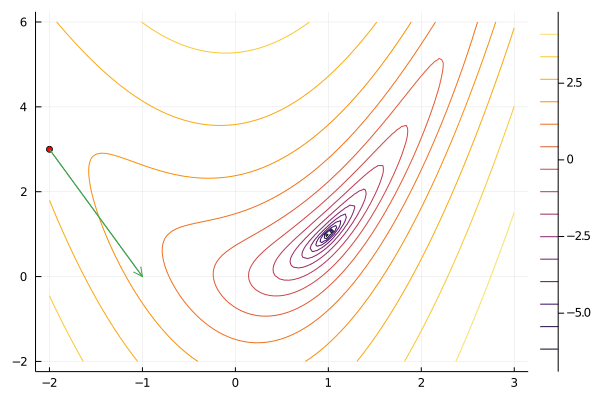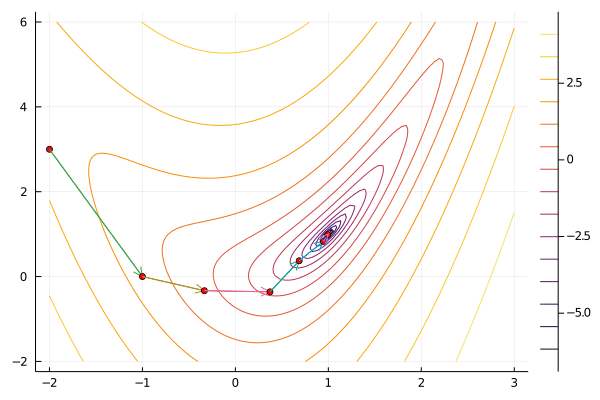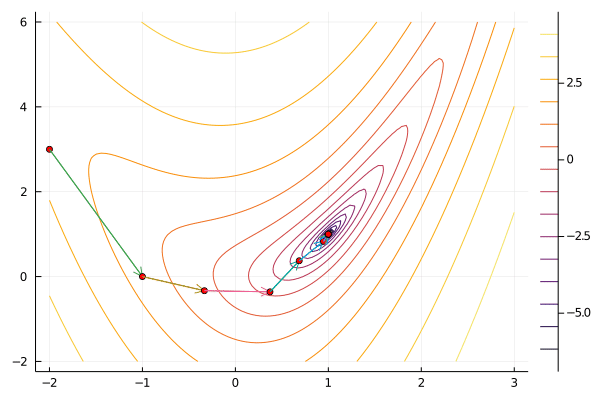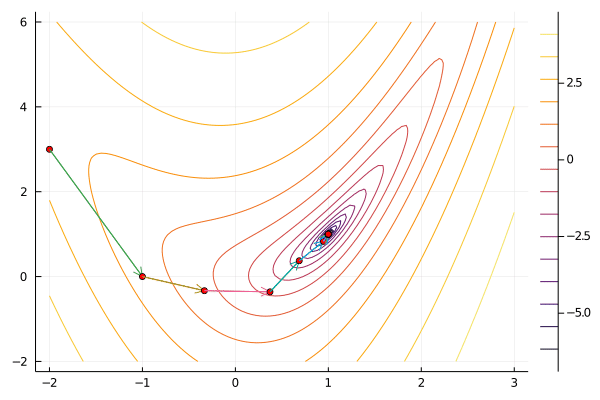
Newton’s method tends to take relatively few iterations to converge for well-behaved functions. It does have the disadvantage that hessian and its inverse can be time consuming to compute, especially when the dimension of $x$ is large. Newton’s method can be unstable for functions that are not well approximated by their second expansion. This problem can be mitigated by combining Newton’s method with a line search or trust region.
Line search¶
Line searches consist of approximately minimizing $f$ along a given direction instead of updating $x$ with a fixed step size. For Newton’s method, instead of setting $x_{new} = x - (D^2f_x)^{-1} Df_x$, set $x_{new} \approx \argmin_{\delta} f(x - \delta (D^2f_x)^{-1} Df_x)$ where $\delta$ is a scalar. This one dimensional problem can be solved fairly quickly. Line search can also be combined with gradient descent.
Trust region¶
Instead of setting to the unconstrained minimizer of a local second order approximation, trust region methods introduce an region near $x$ where the approximation is trusted, and set Often $TR(x) = {\tilde{x} : \norm{x - \tilde{x}} < r}$. The radius of the trust region is then increased or decreased depending on $f(x_{new})$.
Quasi-Newton¶
Quasi-Newton methods (in particular the BFGS algorithm) are probably the most commonly used nonlinear optimization algorithm. Quasi-Newton methods are similar to Newton’s method, except instead of evaluating the hessian directly, quasi-Newton methods build an approximation to the hessian from repeated evaluations of $Df_x$ at different $x$.
Optim.jl contains all the algorithms mentioned above. Their advice on choice of algorithm is worth following..
Details matter in practice¶
In each of the algorithms above, we were somewhat cavalier with details like how to adjust step sizes and trust regions and what it means to approximately minimize during a line search. In practice these details can be quite important for how long an algorithm takes and whether it succeeds or fails. Different implementations of algorithms have different details. Often the details can be adjusted through some options. It can be worthwhile to try multiple implementations and options to get the best performance.
Constrained optimization¶
Constrained optimization is a bit harder than unconstrained, but uses similar ideas. For simple bound constraints, like $x\geq 0$ it is often easiest to simply transform to an unconstrained case by optimizing over $y = \log(x)$ instead.
For problems with equality constraints, one can apply Newton’s method to the first order conditions.
The difficult case is when there are inequality constraints. Just like when solving analytically, the difficulty is figuring out which constraints bind and which do not. For inequality constraints, we will consider problems written in the form:
Interior Point Methods¶
Interior point methods circumvent the problem of figuring out which constraints bind by approaching the optimum from the interior of the feasible set. To do this, the interior point method applies Newton’s method to a modified version of the first order condition. The unmodified first order conditions can be written A difficulty with these conditions is that solving them can require guessing and checking which combinations of constraints bind and which do not. Interior point methods get around this problem by beginning with an interior $x$ and $\lambda$ such that $\lambda>0$ and $c(x)>0$. They are then updated by applying Newton’s method to the equations where there is now a $\mu$ in place of $0$ in the second equation. $x$ and $\lambda$ are updated according to Newton’s method for this system of equations. In particular, $x_{new} = x + \Delta_x$ and $\lambda_{new}= \lambda + \Delta_\lambda$, where Over iterations $\mu$ is gradually decreased toward $0$. Here is one simple implementation.
markdown && printfunc("interiorpoint","constrained_optimizers.jl")
"""
interiorpoint(f, x0, c;
L = (x,λ)->(f(x) - dot(λ,c(x))),
∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x),
∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x),
∇c = x->ForwardDiff.jacobian(c,x),
tol=1e-4, maxiter = 1000,
μ0 = 1.0, μfactor = 0.2,
xrange=[-2., 3.],
yrange=[-2.,6.], animate=true)
Find the minimum of function `f` subject to `c(x) >= 0` using a
primal-dual interior point method.
# Arguments
- `f` function to minimizie
- `x0` starting value. Must have c(x0) > 0
- `c` constraint function. Must return an array.
- `L = (x,λ)->(f(x) - dot(λ,c(x)))` Lagrangian
- `∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x)` Derivative of Lagrangia
n wrt `x`
- `∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x)` Hessian of Lagrangian wr
t `x`
- `∇c = x->ForwardDiff.jacobian(c,x)` Jacobian of constraints
- `tol` convergence tolerance
- `μ0` initial μ
- `μfactor` how much to decrease μ by
- `xrange` range of x-axis for animation
- `yrange` range of y-axis for animation
- `animate` whether to create an animation (if true requires length(x)==2)
- `verbosity` higher values result in more printed output during search. 0
for no output, any number > 0 for some.
# Returns
- `(fmin, xmin, iter, info, animate)` tuple consisting of minimal function
value, minimizer, number of iterations, and convergence info
"""
function interiorpoint(f, x0, c;
L = (x,λ)->(f(x) - dot(λ,c(x))),
∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x),
∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x),
∇c = x->ForwardDiff.jacobian(c,x),
tol=1e-4, maxiter = 1000,
μ0 = 1.0, μfactor = 0.2,
xrange=[-2., 3.],
yrange=[-2.,6.], animate=true, verbosity=0)
fold = f(x0)
xold = x0
all(c(x0).>0) || error("interiorpoint requires a starting value that stri
ctly satisfies all constraints")
μ = μ0
λ = μ./c(x0)
xchange=Inf
fchange=Inf
iter = 0
μiter = 0
stuck=0
animate = animate && length(x0)==2
if animate
# make a contour plot of the function we're minimizing. This is for
# illustrating; you wouldn't have this normally
ct = contour(range(xrange[1],xrange[2], length=100),
range(yrange[1],yrange[2], length=100),
(x,y) -> log(f([x,y])))
plot!(ct, xrange, 2.5 .- xrange) # add constraint
anim = Animation()
end
foc = [∇ₓL(xold,λ); λ.*c(xold)]
while(iter < maxiter && ((xchange>tol) || (fchange>tol) || (stuck>0)
|| norm(foc)>tol || μ>tol) )
# Calculate the direction for updating x and λ
Dc = ∇c(xold)
cx = c(xold)
foc = ∇ₓL(xold, λ)
H = ∇²ₓL(xold,λ)
Δ = [H -Dc'; λ'*Dc diagm(cx)] \ [-foc; μ .- cx.*λ]
# Find a step size such that λ>=0 and c(x)>=0
# The details here could surely be improved
α = 1.0
acceptedstep = false
λold = copy(λ)
x = copy(xold)
while (α > 1e-10)
x = xold + α*Δ[1:length(xold)]
λ = λold + α*Δ[(length(xold)+1):length(Δ)]
if (all(λ.>=0) && all(c(x).>=0))
acceptedstep=true
break
end
α *= 0.5
end
if !acceptedstep
stuck = 1
break
end
fnew = f(x)
if (animate)
scatter!(ct, [xold[1]],[xold[2]], markercolor=:red, legend=false,
xlims=xrange, ylims=yrange)
quiver!(ct, [xold[1]],[xold[2]], quiver=([α*Δ[1]],[α*Δ[2]]), legend=f
alse,
xlims=xrange, ylims=yrange)
frame(anim)
end
xchange = norm(x-xold)
fchange = abs(fnew-fold)
μiter += 1
# update μ (the details here could also be improved)
foc = ∇ₓL(x,λ)
if (μiter>10 || (norm(foc)< μ && λ'*c(x)<10*μ))
μ *= μfactor
μiter = 0
end
xold = x
fold = fnew
if verbosity>0
print("Iter $iter: f=$fnew, λ=$λ, c(x)=$(c(x)), μ=$μ, norm(foc)=$(nor
m(foc))\n")
end
iter += 1
end
if (iter >= maxiter)
info = "Maximum iterations reached"
elseif (stuck>0)
info = "Failed to find feasible step for " * string(stuck) * " iteratio
ns."
else
info = "Convergence."
end
return(fold, xold, iter, info, anim)
end
f = banana(1.0,1.0)
x0 = [3.0, 0.0]
function constraint(x)
[x[1] + x[2] - 2.5]
end
constraint (generic function with 1 method)
result = interiorpoint(f, x0, constraint; maxiter=100)
gif(result[5], "ip.gif", fps=5);
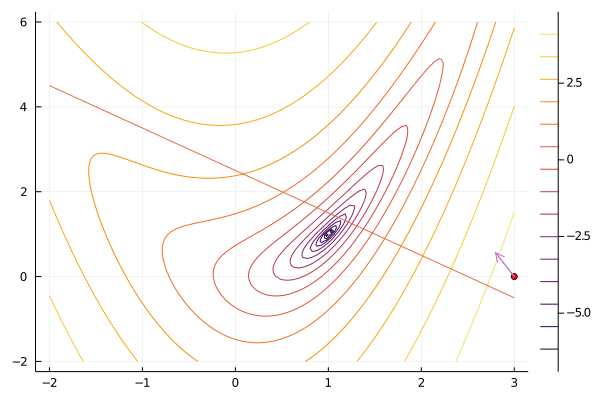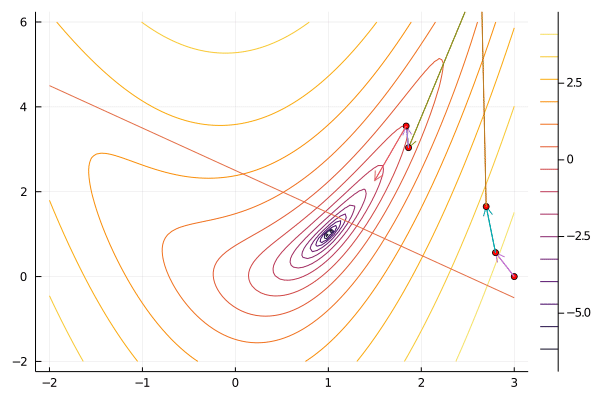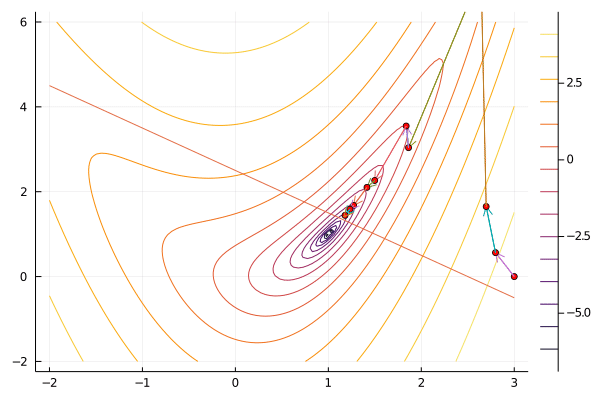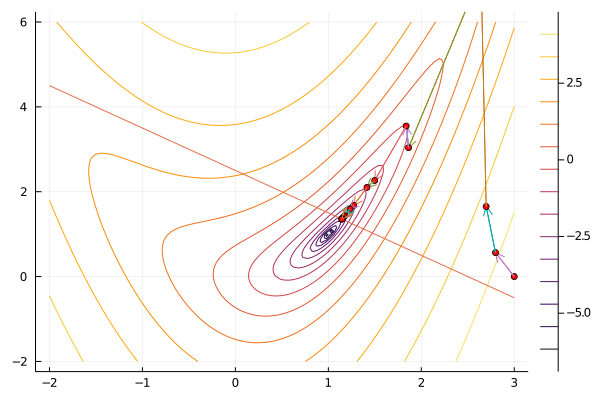
Optim.jl includes an interior point method. IPOPT is another popular implementation. As above, the details of the algorithm can be important in practice. It can be worthwhile to experiment with different methods for updating $\mu$, using a more sophisticated line search or trust region, and perhaps replacing the computation of the hessian with a quasi-Newton approximation.
It has been proven that interior point methods converge relatively quickly for convex optimization problems.
Sequential quadratic programming¶
Sequential quadratic programming relies on the fact that there are efficient methods to compute the solution to quadratic programs — optimization problems with quadratic objective functions and linear constraints. We can then solve a more general optimization problem by solving a sequence of quadratic programs that approximate the original problem.
Sequential quadratic programming is like a constrained version of Newton’s method. Given a current $x$ and $\lambda$ the new $x$ solves and the new $\lambda$ is set to the value of the multipliers for this problem.
This quadratic program (an optimization problem with a quadratic objective function and linearc onstraints) can be solved fairly efficiently if $(D^2 f_x + D^2 (\lambda^T c)_x)$ is positive semi-definite.
Info
Most for Convex program solvers are designed to accept semidefinite
programs instead of quadratic programs. A quadratic program can be
re-written as a semidefinite
program. A solver such as
SCS, ECOS, or Mosek can then be used. Fortunately, Convex.jl will
automatically take care of any necessary transformation.
One could also incorporate a trust region or line search into the above algorithm. Here is one simple implementation.
using Convex, ECOS
Error: ArgumentError: Package Convex not found in current path:
- Run `import Pkg; Pkg.add("Convex")` to install the Convex package.
markdown && printfunc("sequentialquadratic","constrained_optimizers.jl")
"""
sequentialquadratic(f, x0, c;
∇f = x->ForwardDiff.gradient(f,x),
∇c = x->ForwardDiff.jacobian(c,x),
L = (x,λ)->(f(x) - dot(λ,c(x))),
∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x),
∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x),
tol=1e-4, maxiter = 1000,
trustradius=1.0, xrange=[-2., 3.],
yrange=[-2.,6.], animate=true, verbosity=1)
Find the minimum of function `f` subject to `c(x) ≥ 0` by sequential quadra
tic programming.
# Arguments
- `f` function to minimizie
- `x0` starting value. Must have c(x0) > 0
- `c` constraint function. Must return an array.
- `∇f = x->ForwardDiff.gradient(f,x)`
- `∇c = x->ForwardDiff.jacobian(c,x)` Jacobian of constraints
- `L = (x,λ)->(f(x) - dot(λ,c(x)))` Lagrangian
- `∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x)` Derivative of Lagrangia
n wrt `x`
- `∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x)` Hessian of Lagrangian wr
t `x`
- `tol` convergence tolerance
- `maxiter`
- `trustradius` initial trust region radius
- `xrange` range of x-axis for animation
- `yrange` range of y-axis for animation
- `animate` whether to create an animation (if true requires length(x)==2)
- `verbosity` higher values result in more printed output during search. 0
for no output, any number > 0 for some.
# Returns
- `(fmin, xmin, iter, info, animate)` tuple consisting of minimal function
value, minimizer, number of iterations, and convergence info
"""
function sequentialquadratic(f, x0, c;
∇f = x->ForwardDiff.gradient(f,x),
∇c = x->ForwardDiff.jacobian(c,x),
L = (x,λ)->(f(x) - dot(λ,c(x))),
∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x
),
∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x)
,
tol=1e-4, maxiter = 1000,
trustradius=1.0,
xrange=[-2., 3.],
yrange=[-2.,6.], animate=true, verbosity=1)
fold = f(x0)
xold = x0
xchange=Inf
fchange=Inf
iter = 0
μiter = 0
stuck=0
animate = animate && length(x0)==2
if animate
# make a contour plot of the function we're minimizing. This is for
# illustrating; you wouldn't have this normally
ct = contour(range(xrange[1],xrange[2], length=100),
range(yrange[1],yrange[2], length=100),
(x,y) -> log(f([x,y])))
plot!(ct, xrange, 2.5 .- xrange) # add constraint
anim = Animation()
end
Dc = ∇c(xold)
Df = ∇f(xold)
λ = (Dc*Dc') \ Dc*Df
foc = ∇ₓL(xold,λ)
fold = f(xold)
negsquared(x) = x < 0 ? x^2 : zero(x)
merit(x) = f(x) + 1000.0*sum(negsquared.(c(x)))
while(iter < maxiter && ((xchange>tol) || (fchange>tol) || (stuck>0)
|| norm(foc)>tol) )
Df = ∇f(xold)
Dc = ∇c(xold)
cx = c(xold)
H = ∇²ₓL(xold,λ)
# QP will fail with if H not positive definite
if !(isposdef(H))
v,Q = eigen(H)
Hp = Symmetric(Q*Diagonal(max.(v,one(eltype(v))*1e-8))*Q')
else
Hp = H
end
# set up and solve our QP
Δ = Variable(length(xold))
problem = minimize(Df'*Δ + 0.5*quadform(Δ,Hp), [cx + Dc*Δ >= 0; norm(Δ)
<=trustradius])
solve!(problem, ECOS.Optimizer(verbose=verbosity))
λ .= problem.constraints[1].dual
xnew = xold .+ Δ.value
if (animate)
scatter!(ct, [xold[1]],[xold[2]], markercolor=:red, legend=false,
xlims=xrange, ylims=yrange)
quiver!(ct, [xold[1]],[xold[2]], quiver=([Δ.value[1]],[Δ.value[2]]),
legend=false,
xlims=xrange, ylims=yrange)
frame(anim)
end
# decide whether to accept new point and whether to adjust trust region
if (merit(xnew) < merit(xold))
stuck = 0
foc = [∇ₓL(xold,λ); λ.*c(xold)]
if (problem.constraints[2].dual>1e-4) # trust region binding
trustradius *= 3/2
end
else
stuck += 1
trustradius *= 2/3
if (stuck>=20)
break
end
end
xchange = norm(xnew-xold)
fchange = abs(f(xnew)-f(xold))
xold = xnew
if verbosity>0
print("Iter $iter: f=$(f(xold)), λ=$λ, c(x)=$(c(xold)), TR=$trustradi
us, norm(foc)=$(norm(foc))\n")
end
iter += 1
end
if (iter >= maxiter)
info = "Maximum iterations reached"
elseif (stuck>0)
info = "Failed to find feasible step for " * string(stuck) * " iteratio
ns."
else
info = "Convergence."
end
return(f(xold), xold, iter, info, anim)
end
x0 = [0.0, 6.0]
result = sequentialquadratic(f, x0, constraint; maxiter=100, verbosity=0);
gif(result[5], "sqp.gif", fps=5);
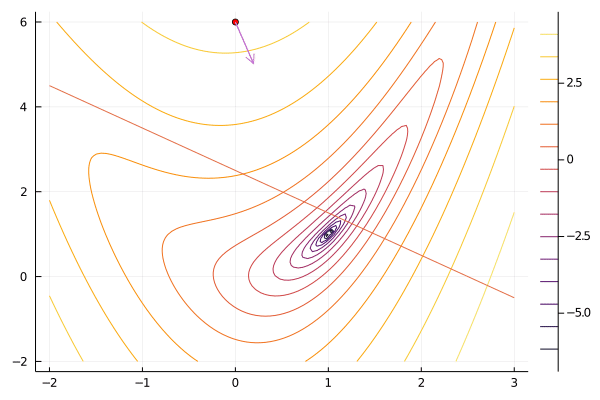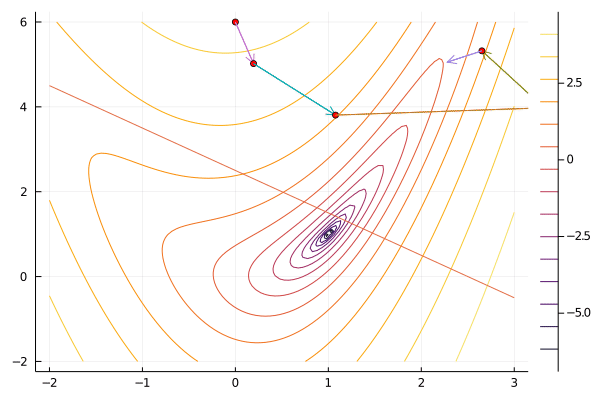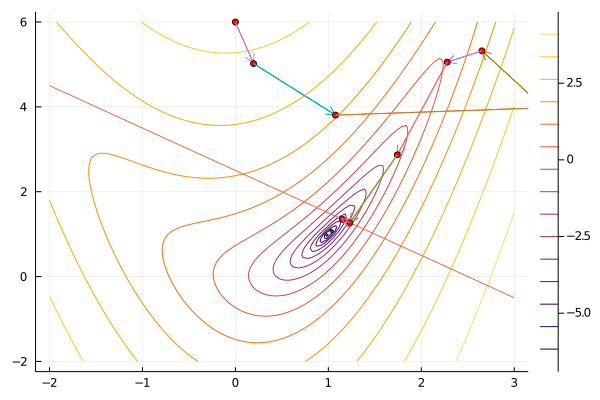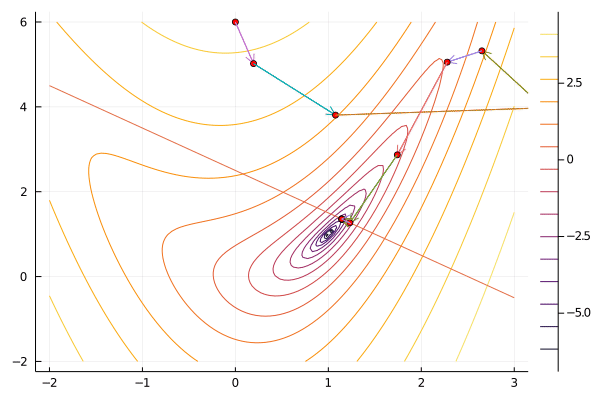
Compared to interior point methods, sequential quadratic programming has the advantage of not needing a feasible point to begin, and often taking fewer iteration. Like Newton’s method, sequential quadratic programming has local quadratic convergence. A downside of sequential quadratic programming is that solving the quadratic program at each step can take considerably longer than solving the system of linear equations that interior point methods and Newton methods require.
SLQP active Set¶
SLQP active set methods use a linear approximation to the optimization problem to decide which constraints are “active” (binding). In each iteration, a linear approximation to the original problem is first solved. The constraints that bind in linear approximation are then assumed to bind in the full problem, and we solve an equality constrained quadratic program to determine the next step.
Byrd and Waltz (2011)[bryd2011] for more details and an extension to the SLQP method.
markdown && printfunc("slqp","constrained_optimizers.jl")
"""
slqp(f, x0, c;
∇f = x->ForwardDiff.gradient(f,x),
∇c = x->ForwardDiff.jacobian(c,x),
L = (x,λ)->(f(x) - dot(λ,c(x))),
∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x),
∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x),
tol=1e-4, maxiter = 1000,
trustradius=1.0, xrange=[-2., 3.],
yrange=[-2.,6.], animate=true, verbosity=1)
Find the minimum of function `f` subject to `c(x) ≥ 0` by sequential
linear quadratic programming.
See
https://en.wikipedia.org/wiki/Sequential_linear-quadratic_programming
for algorithm information.
# Arguments
- `f` function to minimizie
- `x0` starting value. Must have c(x0) > 0
- `c` constraint function. Must return an array.
- `∇f = x->ForwardDiff.gradient(f,x)`
- `∇c = x->ForwardDiff.jacobian(c,x)` Jacobian of constraints
- `L = (x,λ)->(f(x) - dot(λ,c(x)))` Lagrangian
- `∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x)` Derivative of Lagrangia
n wrt `x`
- `∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x)` Hessian of Lagrangian wr
t `x`
- `tol` convergence tolerance
- `maxiter`
- `trustradius` initial trust region radius
- `xrange` range of x-axis for animation
- `yrange` range of y-axis for animation
- `animate` whether to create an animation (if true requires length(x)==2)
- `verbosity` higher values result in more printed output during search. 0
for no output, any number > 0 for some.
# Returns
- `(fmin, xmin, iter, info, animate)` tuple consisting of minimal function
value, minimizer, number of iterations, and convergence info
"""
function slqp(f, x0, c;
∇f = x->ForwardDiff.gradient(f,x),
∇c = x->ForwardDiff.jacobian(c,x),
L = (x,λ)->(f(x) - dot(λ,c(x))),
∇ₓL = (x,λ)->ForwardDiff.gradient(z->L(z,λ), x),
∇²ₓL= (x,λ)->ForwardDiff.hessian(z->L(z,λ), x),
tol=1e-4, maxiter = 1000,
trustradius=1.0,
xrange=[-2., 3.],
yrange=[-2.,6.], animate=true, verbosity=1)
fold = f(x0)
xold = x0
xchange=Inf
fchange=Inf
iter = 0
μiter = 0
stuck=0
lptrustradius = trustradius
animate = animate && length(x0)==2
if animate
# make a contour plot of the function we're minimizing. This is for
# illustrating; you wouldn't have this normally
ct = contour(range(xrange[1],xrange[2], length=100),
range(yrange[1],yrange[2], length=100),
(x,y) -> log(f([x,y])))
plot!(ct, xrange, 2.5 .- xrange) # add constraint
anim = Animation()
end
Dc = ∇c(xold)
Df = ∇f(xold)
cx = c(xold)
λ = (Dc*Dc') \ Dc*Df
foc = [∇ₓL(xold,λ); λ.*cx]
fold = f(xold)
negsquared(x) = x < 0 ? x^2 : zero(x)
merit(x) = f(x) + sum(negsquared.(c(x)))
while(iter < maxiter && ((xchange>tol) || (fchange>tol) || (stuck>0)
|| (norm(foc)>tol)) )
Df = ∇f(xold)
Dc = ∇c(xold)
cx = c(xold)
H = ∇²ₓL(xold,λ)
# set up and solve linear program for finding active set (binding
# constraints)
Δ = Variable(length(xold))
problem = minimize(Df'*Δ, [cx + Dc*Δ >= 0,
Δ <= lptrustradius,
-lptrustradius <= Δ])
solve!(problem, ECOS.Optimizer(verbose=verbosity))
while (Int(problem.status)!=1 && lptrustradius <=1e4)
lptrustradius *= 2
problem = minimize(Df'*Δ, [cx + Dc*Δ >= 0,
Δ <= lptrustradius,
-lptrustradius <= Δ])
solve!(problem, ECOS.Optimizer(verbose=verbosity))
end
if isa(problem.constraints[1].dual, AbstractArray)
active = vec(problem.constraints[1].dual .> tol)
else
active = [problem.constraints[1].dual .> tol]
end
# set up and solve our QP
Δ = Variable(length(xold))
if !(isposdef(H))
Hp = zero(H)
else
Hp = H
end
if any(active)
problem = minimize(Df'*Δ + 0.5*quadform(Δ,Hp), [cx[active] + Dc[activ
e,:]*Δ >= 0, norm(Δ)<=trustradius])
solve!(problem, ECOS.Optimizer(verbose=verbosity))
λ[active] .= problem.constraints[1].dual
λ[.!active] .= zero(eltype(λ))
else
problem = minimize(Df'*Δ + 0.5*quadform(Δ,Hp), [norm(Δ)<=trustradius]
)
solve!(problem, ECOS.Optimizer(verbose=verbosity))
λ = zero(cx)
end
xnew = xold .+ Δ.value
if (animate)
scatter!(ct, [xold[1]],[xold[2]], markercolor=:red, legend=false,
xlims=xrange, ylims=yrange)
quiver!(ct, [xold[1]],[xold[2]], quiver=([Δ.value[1]],[Δ.value[2]]),
legend=false,
xlims=xrange, ylims=yrange)
frame(anim)
end
# decide whether to accept new point and whether to adjust trust region
if (merit(xnew) < merit(xold))
stuck = 0
foc = [∇ₓL(xold,λ); λ.*c(xold)]
if (problem.constraints[end].dual>1e-4) # trust region binding
trustradius *= 3/2
end
else
stuck += 1
trustradius *= 2/3
if (stuck>=20)
break
end
end
xchange = norm(xnew-xold)
fchange = abs(f(xnew)-f(xold))
xold = xnew
if verbosity>0
print("Iter $iter: f=$(f(xold)), λ=$λ, c(x)=$(c(xold)),TR=$trustradiu
s, norm(foc)=$(norm(foc)), $xchange , $fchange, $stuck\n")
end
iter += 1
end
if (iter >= maxiter)
info = "Maximum iterations reached"
elseif (stuck>0)
info = "Failed to find feasible step for " * string(stuck) * " iteratio
ns."
else
info = "Convergence."
end
return(f(xold), xold, iter, info, anim)
end
x0 = [-1.0, 6.0]
result = slqp(f, x0, constraint; maxiter=100, verbosity=0);
gif(result[5], "slqp.gif", fps=5);
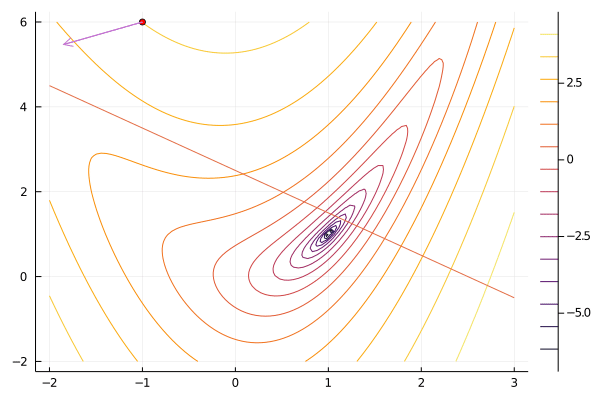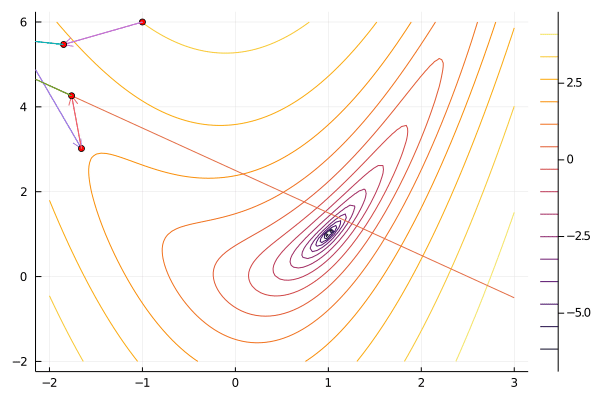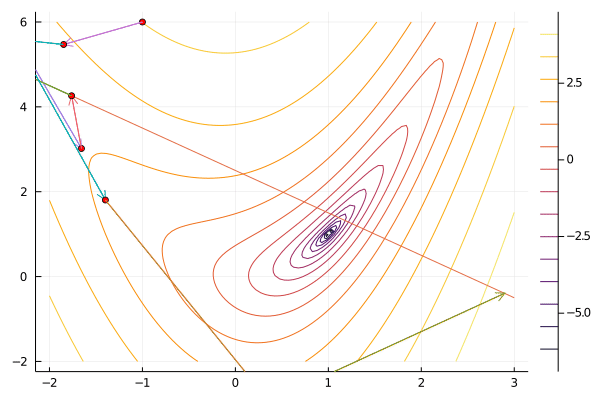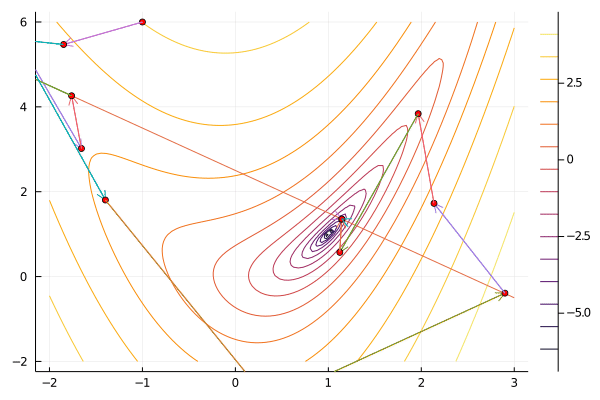
Augmented Lagrangian¶
Augmented Lagragian methods convert a constrained minimization problem to an unconstrained problem by adding a penalty that increases with the constraint violation to the Lagrangian.
Barrier methods¶
Barrier methods refer to adding a penalty that increases toward
$\infty$ as the constraints get close to violated (such as
$\log(c(x))$). Barrier methods are closely related to interior point
methods. Applying Newton’s method to a log-barrier penalized problem
gives rise to something very similar to our interiorpoint algorithm
above.
Strategies for global optimization¶
The above algorithms will all converge to local minima. Finding a
global minimum is generally very hard. There are a few algorithms that
have been proven to converge to a global optimum, such a DIRECT-L in
NLopt. However, these algorithms are prohibitively time-consuming
for even moderate size problems.
Randomization is a good strategy for avoiding local minima. Some algorithms with randomization, like simulated annealing, can be shown to converge to the global optimum with high probability. In practice, these are also often too inefficient for moderate size problems.
A good practical approach is to use an algorithm that combines randomization with some model-based search. A common approach is to use a variant of Newton’s method starting from a bunch of randomly chosen initial values.
Algorithms that combine a linear or quadratic approximation to the objective function with some randomness in the search direction can also be useful. An example is stochastic gradient descent, which is often used to fit neural networks. I have had good experience with CMA-ES. It worked well to estimate the finite mixture model in EFS (2015)1.
Bayesian methods can also be used for optimization and will naturally
include some randomization in their search. Hamiltonian Monte-Carlo
methods, which incorporate gradient information in their search, are
likely to be efficient. See
DynamicHMC.jl.
References¶
-
Liran Einav, Amy Finkelstein, and Paul Schrimpf. The Response of Drug Expenditure to Nonlinear Contract Design: Evidence from Medicare Part D *. The Quarterly Journal of Economics, 130:841–899, 02 2015. URL: https://doi.org/10.1093/qje/qjv005, arXiv:http://oup.prod.sis.lan/qje/article-pdf/130/2/841/17097031/qjv005.pdf, doi:10.1093/qje/qjv005. ↩