
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License
About this document¶
This document was created using Weave.jl. The code is available in on github. The same document generates both static webpages and associated jupyter notebook.
Extremum Estimation¶
Many, perhaps most, estimators in econometrics are extrumem estimators. That is, many estimators are defined by
where $\hat{Q}_n(\theta)$ is some objective function that depends on data. Examples include maximum likelihood,
GMM,
and nonlinear least squares
See Newey and McFadden (1994)1 for more details and examples.
Example: logit¶
As a simple example, let’s look look at some code for estimating a logit.
using Distributions, Optim, BenchmarkTools
import ForwardDiff
function simulate_logit(observations, β)
x = randn(observations, length(β))
y = (x*β + rand(Logistic(), observations)) .>= 0.0
return((y=y,x=x))
end
function logit_likelihood(β,y,x)
p = map(xb -> cdf(Logistic(),xb), x*β)
sum(log.(ifelse.(y, p, 1.0 .- p)))
end
n = 500
k = 3
β0 = ones(k)
(y,x) = simulate_logit(n,β0)
Q = β -> -logit_likelihood(β,y,x)
Q(β0)
247.02307703978195
Now we maximize the likelihood using a few different algorithms from Optim.jl
@time optimize(Q, zeros(k), NelderMead())
@time optimize(Q, zeros(k), BFGS(), autodiff = :forward)
@time optimize(Q, zeros(k), NewtonTrustRegion(), autodiff =:forward)
0.002197 seconds (1.26 k allocations: 2.086 MiB)
0.733200 seconds (2.60 M allocations: 136.030 MiB, 99.83% compilation tim
e)
1.273711 seconds (4.01 M allocations: 207.743 MiB, 3.92% gc time, 99.88%
compilation time)
* Status: success
* Candidate solution
Final objective value: 2.370103e+02
* Found with
Algorithm: Newton's Method (Trust Region)
* Convergence measures
|x - x'| = 4.95e-08 ≰ 0.0e+00
|x - x'|/|x'| = 4.13e-08 ≰ 0.0e+00
|f(x) - f(x')| = 1.42e-13 ≰ 0.0e+00
|f(x) - f(x')|/|f(x')| = 6.00e-16 ≰ 0.0e+00
|g(x)| = 6.75e-14 ≤ 1.0e-08
* Work counters
Seconds run: 0 (vs limit Inf)
Iterations: 6
f(x) calls: 7
∇f(x) calls: 7
∇²f(x) calls: 7
Aside: Reverse mode automatic differentiation¶
For functions $f:\R^n → \R^m$, the work for forward automatic differentiation increases linearly with $n$. This is because forward automatic differentiation applies the chain rule to each of the $n$ inputs. An alternative, is reverse automatic differentiation. Reverse automatic differentiation is also based on the chain rule, but it works backward from $f$ through intermediate steps back to $x$. The work needed here scales linearly with $m$. Since optimization problems have $m=1$, reverse automatic differentiation can often work well. The downsides of reverse automatic differentiation are that: (1) it can require a large amount of memory and (2) it is more difficult to implement. There are handful of Julia packages that provide reverse automatic differentiation, but they have some limitations in terms of what functions thay can differentiate. Flux.jl and Zygote.jl are two such packages.
using Optim, BenchmarkTools
import Zygote
dQr = β->Zygote.gradient(Q,β)[1]
dQf = β->ForwardDiff.gradient(Q,β)
@show dQr(β0) ≈ dQf(β0)
@btime dQf(β0)
@btime dQr(β0)
n = 500
k = 200
β0 = ones(k)
(y,x) = simulate_logit(n,β0)
Q = β -> -logit_likelihood(β,y,x)
dQr = β->Zygote.gradient(Q,β)[1]
dQf = β->ForwardDiff.gradient(Q,β)
@show dQr(β0) ≈dQf(β0)
@btime dQf(β0);
@btime dQr(β0);
dQr(β0) ≈ dQf(β0) = true
23.387 μs (9 allocations: 47.77 KiB)
66.415 μs (88 allocations: 143.73 KiB)
dQr(β0) ≈ dQf(β0) = true
6.389 ms (141 allocations: 2.56 MiB)
198.482 μs (89 allocations: 914.84 KiB)
Review of extremum estimator theory¶
This is based on Newey and McFadden (1994)1. You should already be familiar with this from 627, so we will just state some basic “high-level” conditions for consistency and asymptotic normality.
Consistency¶
Theorem: consistency for extremum estimators
Assume
-
$\hat{Q}_n(\theta)$ converges uniformly in probability to $Q_0(\theta)$
-
$Q_0(\theta)$ is uniquely maximized at $\theta_0$.
-
$\Theta$ is compact and $Q_0(\theta)$ is continuous.
Then $\hat{\theta} \inprob \theta_0$
Asymptotic normality¶
Theorem: asymptotic normality for extremum estimators
Assume
-
$\hat{\theta} \inprob \theta_0$
-
$\theta_0 \in interior(\Theta)$
-
$\hat{Q}n(\theta)$ is twice continuously differentiable in open $N$ containing $\theta$ , and $\sup \left\Vert \nabla^2 \hat{Q}_n(\theta) - H(\theta) \right\Vert \inprob 0$ with $H(\theta_0)$ nonsingular
-
$\sqrt{n} \nabla \hat{Q}_n(\theta_0) \indist N(0,\Sigma)$
Then $\sqrt{n} (\hat{\theta} - \theta_0) \indist N\left(0,H^{-1} \Sigma H^{-1} \right)$
Implementing this in Julia using automatic differentiation is straightforward.
function logit_likei(β,y,x)
p = map(xb -> cdf(Logistic(),xb), x*β)
log.(ifelse.(y, p, 1.0 .- p))
end
function logit_likelihood(β,y,x)
mean(logit_likei(β,y,x))
end
n = 100
k = 3
β0 = ones(k)
(y,x) = simulate_logit(n,β0)
Q = β -> -logit_likelihood(β,y,x)
optres = optimize(Q, zeros(k), NewtonTrustRegion(), autodiff =:forward)
βhat = optres.minimizer
function asymptotic_variance(Q,dQi, θ)
gi = dQi(θ)
Σ = gi'*gi/size(gi)[1]
H = ForwardDiff.hessian(Q,θ)
invH = inv(H)
(variance=invH*Σ*invH, Σ=Σ, invH=invH)
end
avar=asymptotic_variance(θ->logit_likelihood(θ,y,x),
θ->ForwardDiff.jacobian(β->logit_likei(β,y,x),θ),βhat)
display( avar.variance/n)
display( -avar.invH/n)
display(inv(avar.Σ)/n)
3×3 Matrix{Float64}:
0.0671014 0.0100753 0.0137901
0.0100753 0.0485069 0.0170796
0.0137901 0.0170796 0.0584229
3×3 Matrix{Float64}:
0.0763673 0.0221305 0.0219578
0.0221305 0.0665209 0.0200308
0.0219578 0.0200308 0.0777187
3×3 Matrix{Float64}:
0.0894934 0.0392628 0.0326049
0.0392628 0.0927231 0.0234643
0.0326049 0.0234643 0.103806
For maximum likelihood, the information equality says $-H = \Sigma$, so the three expressions above have the same probability limit, and are each consistent estimates of the variance of $\hat{\theta}$.
The code above is for demonstration and learning. If we really wanted to estimate a logit for research, it would be better to use a well-tested package. Here’s how to estimate a logit using GLM.jl.
using GLM, DataFrames
df = DataFrame(x, :auto)
df[!,:y] = y
glmest=glm(@formula(y ~ -1 + x1+x2+x3), df, Binomial(),LogitLink())
display( glmest)
display( vcov(glmest))
StatsModels.TableRegressionModel{GeneralizedLinearModel{GLM.GlmResp{Vector{
Float64}, Binomial{Float64}, LogitLink}, GLM.DensePredChol{Float64, Cholesk
y{Float64, Matrix{Float64}}}}, Matrix{Float64}}
y ~ 0 + x1 + x2 + x3
Coefficients:
───────────────────────────────────────────────────────────────
Coef. Std. Error z Pr(>|z|) Lower 95% Upper 95%
───────────────────────────────────────────────────────────────
x1 0.918876 0.0878288 10.46 <1e-24 0.746735 1.09102
x2 0.976711 0.0893682 10.93 <1e-27 0.801553 1.15187
x3 0.949527 0.0889833 10.67 <1e-25 0.775123 1.12393
───────────────────────────────────────────────────────────────
3×3 Matrix{Float64}:
0.00771389 0.0022444 0.00198692
0.0022444 0.00798667 0.00209977
0.00198692 0.00209977 0.00791803
Delta method¶
In many models, we are interested in some transformation of the parameters in addition to the parameters themselves. For example, in a logit, we might want to report marginal effects in addition to the coefficients. In structural models, we typically use the parameter estimates to conduct counterfactual simulations. In many situations we are more interested these transformation(s) of parameters than in the parameters themselves. The delta method is one convenient way to approximate the distribution of transformations of the model parameters.
Theorem: Delta method
Assume:
-
$\sqrt{n} (\hat{\theta} - \theta_0) \indist N(0,\Omega)$
-
$g: \R^k \to \R^m$ is continuously differentiable
Then $\sqrt{n}(g(\hat{\theta}) - g(\theta_0)) \indist N(0, \nabla g(\theta_0)^T \Omega \nabla g(\theta_0)$
The following code uses the delta method to plot a 90% pointwise confidence band around the estimate marginal effect of one of the regressors.
using LinearAlgebra
function logit_mfx(β,x)
out = ForwardDiff.jacobian(x-> map(xb -> cdf(Logistic(),xb), x*β), x)
out = reshape(out, size(out,1), size(x)...)
end
function delta_method(g, θ, Ω)
dG = ForwardDiff.jacobian(θ->g(θ),θ)
dG*Ω*dG'
end
nfx = 100
xmfx = zeros(nfx,3)
xmfx[:,1] .= -3.0:(6.0/(nfx-1)):3.0
mfx = logit_mfx(βhat,xmfx)
vmfx = delta_method(β->diag(logit_mfx(β,xmfx)[:,:,1]), βhat, avar.variance/n)
sdfx = sqrt.(diag(vmfx))
using Plots, LaTeXStrings
#Plots.unicodeplots()
#using PlotlyLight
#plt = Plot()
#plt(x=xmfx[:,1], y=diag(mfx[:,:,1]),
# error_y=Config(:type=>"data",
# :array=>quantile(Normal(),0.95)*sdfx,
# :visible=>true))
#plt.layout.title.text = "Marginal effect of x[1] when x[2:k]=0"
#plt.layout.xaxis.title=L"x_1"
#plt.layout.yaxis.title=L"\frac{\partial}{\partial x_1}P(y=1|x)"
#plt
plot(xmfx[:,1],diag(mfx[:,:,1]),ribbon=quantile(Normal(),0.95)*sdfx,fillalpha=0.5,xlabel=L"x_1", ylabel=L"\frac{\partial}{\partial x_1}P(y=1|x)", legend=false,title="Marginal effect of x[1] when x[2:k]=0")
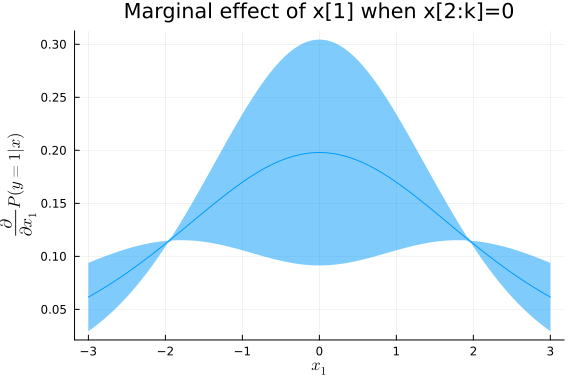
The same approach can be used to compute standard errors and confidence regions for the results of more complicated counterfactual simulations, as long as the associated simulations are smooth functions of the parameters. However, sometimes it might be more natural to write simulations with outcomes that are not smooth in the parameters. For example, the following code uses simulation to calculate the change in the probability of $y$ from adding 0.1 to $x$.
function counterfactual_sim(β, x, S)
function onesim()
e = rand(Logistic(), size(x)[1])
baseline= (x*β .+ e .> 0)
counterfactual= ((x.+0.1)*β .+ e .> 0)
mean(counterfactual.-baseline)
end
mean([onesim() for s in 1:S])
end
ForwardDiff.gradient(β->counterfactual_sim(β,x,10),βhat)
3-element Vector{Float64}:
0.0
0.0
0.0
Here, the gradient is 0 because the simulation function is a step-function. In this situation, an alternative to the delta method is the simulation based approach of Krinsky and Robb (1986)2. The procedure is quite simple. Suppose $\sqrt{n}(\hat{\theta} - \theta_0) \indist N(0,\Omega)$, and you want to an estimate of the distribution of $g(\theta)$. Repeatedly draw $\theta_s \sim N(\hat{\theta}, \Omega/n)$ and compute $g(\theta_s)$. Use the distribution of $g(\theta_s)$ for inference. For example, a 90% confidence interval for $g(\theta)$ would be the 5%-tile of $g(\theta_s)$ to the 95%-tile of $g(\theta_s)$.
Ω = avar.variance/n
Ω = (Ω+Ω')/2 # otherwise, it's not exactly symmetric due to
# floating point roundoff
function kr_confint(g, θ, Ω, simulations; coverage=0.9)
θs = [g(rand(MultivariateNormal(θ,Ω))) for s in 1:simulations]
quantile(θs, [(1.0-coverage)/2, coverage + (1.0-coverage)/2])
end
@show kr_confint(β->counterfactual_sim(β,x,10), βhat, Ω, 1000)
# a delta method based confidence interval for the same thing
function counterfactual_calc(β, x)
baseline = cdf.(Logistic(), x*β)
counterfactual= cdf.(Logistic(), (x.+0.1)*β)
return([mean(counterfactual.-baseline)])
end
v = delta_method(β->counterfactual_calc(β,x), βhat, Ω)
ghat = counterfactual_calc(βhat,x)
@show [ghat + sqrt(v)*quantile(Normal(),0.05), ghat +
sqrt(v)*quantile(Normal(),0.95)]
kr_confint((β->begin
#= /home/paul/.julia/dev/GMMInference/docs/jmd/extremumEstimati
on.jmd:10 =#
counterfactual_sim(β, x, 10)
end), βhat, Ω, 1000) = [0.0432, 0.052305]
[ghat + sqrt(v) * quantile(Normal(), 0.05), ghat + sqrt(v) * quantile(Norma
l(), 0.95)] = [[0.045645901625267424;;], [0.05070264808429101;;]]
2-element Vector{Matrix{Float64}}:
[0.045645901625267424;;]
[0.05070264808429101;;]
References¶
-
Whitney K. Newey and Daniel McFadden. Chapter 36 large sample estimation and hypothesis testing. In Handbook of Econometrics, volume 4 of Handbook of Econometrics, pages 2111 – 2245. Elsevier, 1994. URL: http://www.sciencedirect.com/science/article/pii/S1573441205800054, doi:https://doi.org/10.1016/S1573-4412(05)80005-4. ↩↩
-
Itzhak Krinsky and A. Leslie Robb. On approximating the statistical properties of elasticities. The Review of Economics and Statistics, 68(4):715–719, 1986. URL: http://www.jstor.org/stable/1924536. ↩