
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License
Model¶
Following Kevin Systrom, we adapt the approach of (Bettencourt 2008) to compute real-time rolling estimates of pandemic parameters. (Bettencourt 2008) begin from a SIR model,
To this we add the possibility that not all cases are known. Cases get get detected at rate $I$, so cumulative confirmed cases, $C$, evolves as
Question
Should we add other states to this model? If yes, how? I think using death and hospitalization numbers in estimation makes sense.
The number of new confirmed cases from time $t$ to $t+\delta$ is then:
We will allow for the testing rate, $\tau$, and infection rate, $\beta$, to vary over time.
As in (Bettencourt 2008),
Note
The reproductive number is: $R_t \equiv \frac{S(t)}{N}\frac{\beta(t)}{\gamma}$.
Substituting the expression for $I_t$ into $k_t$, we have
Data¶
We use the same data as the US state model.
The data combines information on
- Daily case counts and deaths from JHU CSSE
- Daily Hospitalizations, recoveries, and testing from the Covid Tracking Project
- Covid related policy changes from Raifman et al
- Movements from Google Mobility Reports
- Hourly workers from Hoembase
Statistical Model¶
The above theoretical model gives a deterministic relationship between $k_t$ and $k_{t-1}$ given the parameters. To bring it to data we must add stochasticity.
Systrom’s approach¶
First we describe what Systrom does. He assumes that $R_{0} \sim Gamma(4,1)$. Then for $t=1, …, T$, he computes $P(R_t|k_{t}, k_{t-1}, … ,k_0)$ iteratively using Bayes’ rules. Specifically, he assumes and that $R_t$ follows a random walk, so the prior of $R_t | R_{t-1}$ is
so that
Note that this computes posteriors of $R_t$ given current and past cases. Future cases are also informative of $R_t$, and you could instead compute $P(R_t | k_0, k_1, …, k_T)$.
The notebook makes some mentions of Gaussian processes. There’s likely some way to recast the random walk assumption as a Gaussian process prior (the kernel would be $\kappa(t,t’) = \min{t,t’} \sigma^2$), but that seems to me like an unusual way to describe it.
Code¶
Let’s see how Systrom’s method works.
First the load data.
using DataFrames, Plots, StatsPlots, CovidSEIR
Plots.pyplot()
df = CovidSEIR.statedata()
df = filter(x->x.fips<60, df)
# focus on 10 states with most cases as of April 1, 2020
sdf = select(df[df[!,:date].==Dates.Date("2020-04-01"),:], Symbol("cases.nyt"), :state) |>
x->sort(x,Symbol("cases.nyt"), rev=true)
states=sdf[1:10,:state]
sdf = select(filter(r->r[:state] ∈ states, df), Symbol("cases.nyt"), :state, :date)
sdf = sort(sdf, [:state, :date])
sdf[!,:newcases] = by(sdf, :state, newcases = Symbol("cases.nyt") => x->(vcat(missing, diff(x))))[!,:newcases]
figs = []
for gdf in groupby(sdf, :state)
f = @df gdf plot(:date, :newcases, legend=:none, linewidth=2, title=unique(gdf.state)[1])
global figs = vcat(figs,f)
end
display(plot(figs[1:9]..., layout=(3,3)))
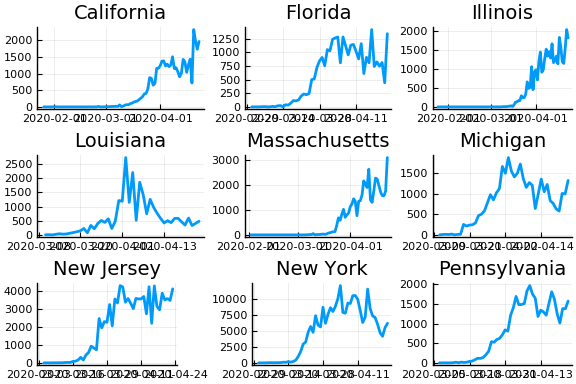
From this we can see that new cases are very noisy. This is especially problematic when cases jump from near 0 to very high values, such as in Illinois. The median value of and variance of new cases, $k_t$, are both $k_{t-1} e^{\gamma(R_t - 1)}$. Only huge changes in $R_t$ can rationalize huge jumps in new cases.
Let’s compute posteriors for each state.
using Interpolations, Distributions
function rtpost(cases, γ, σ, prior0, casepdf)
(rgrid, postgrid, ll) = rtpostgrid(cases)(γ, σ, prior0, casepdf)
w = rgrid[2] - rgrid[1]
T = length(cases)
p = [LinearInterpolation(rgrid, postgrid[:,t]) for t in 1:T]
coverage = 0.9
cr = zeros(T,2)
mu = vec(rgrid' * postgrid*w)
for t in 1:T
l = findfirst(cumsum(postgrid[:,t].*w).>(1-coverage)/2)
h = findlast(cumsum(postgrid[:,t].*w).<(1-(1-coverage)/2))
if !(l === nothing || h === nothing)
cr[t,:] = [rgrid[l], rgrid[h]]
end
end
return(p, mu, cr)
end
function rtpostgrid(cases)
# We'll compute the posterior on these values of R_t
rlo = 0
rhi = 8
steps = 500
rgrid = range(rlo, rhi, length=steps)
Δgrid = range(0.05, 0.95, length=10)
w = rgrid[2] - rgrid[1]
dr = rgrid .- rgrid'
fn=function(γ, σ, prior0, casepdf)
prr = pdf.(Normal(0,σ), dr) # P(r_{t+1} | r_t)
for i in 1:size(prr,1)
prr[i, : ] ./= sum(prr[i,:].*w)
end
postgrid = Matrix{typeof(σ)}(undef,length(rgrid), length(cases)) # P(R_t | k_t, k_{t-1},...)
like = similar(postgrid, length(cases))
for t in 1:length(cases)
if (t==1)
postgrid[:,t] .= prior0.(rgrid)
else
if (cases[t-1]===missing || cases[t]===missing)
pkr = 1 # P(k_t | R_t)
else
λ = max(cases[t-1],1).* exp.(γ .* (rgrid .- 1))
#r = λ*nbp/(1-nbp)
#pkr = pdf.(NegativeBinomial.(r,nbp), cases[t])
pkr = casepdf.(λ, cases[t])
if (all(pkr.==0))
@warn "all pkr=0"
#@show t, cases[t], cases[t-1]
pkr .= 1
end
end
postgrid[:,t] = pkr.*(prr*postgrid[:,t-1])
like[t] = sum(postgrid[:,t].*w)
postgrid[:,t] ./= max(like[t], 1e-15)
end
end
ll = try
sum(log.(like))
catch
-710*length(like)
end
return((rgrid, postgrid, ll))
end
return(fn)
end
for σ in [0.1, 0.25, 1]
γ =1/7
nbp = 0.01
figs = []
for gdf in groupby(sdf, :state)
p, m, cr = rtpost(gdf.newcases, γ, σ, x->pdf(truncated(Gamma(4,1),0,8), x),
(λ,x)->pdf(Poisson(λ),x))
f = plot(gdf.date, m, ribbon=(m-cr[:,1], cr[:,2] - m), title=unique(gdf.state)[1], legend=:none, ylabel="Rₜ")
f = hline!(f,[1.0])
figs = vcat(figs, f)
end
l = @layout [a{.1h};grid(1,1)]
display(plot(plot(annotation=(0.5,0.5, "Poisson & σ=$σ"), framestyle = :none),
plot(figs[1:9]..., layout=(3,3)), layout=l))
end
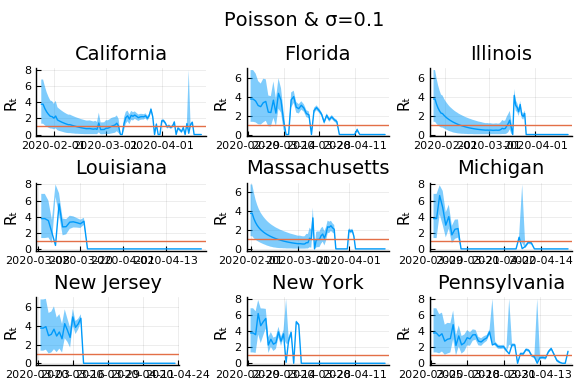
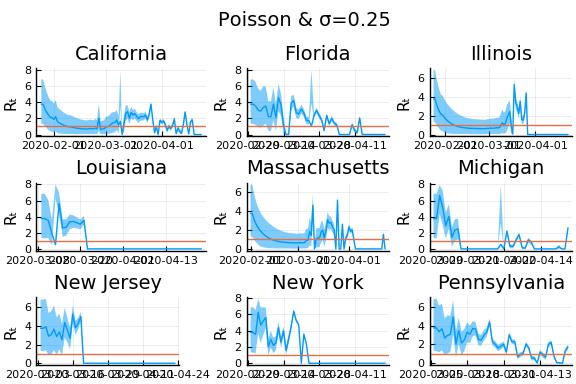
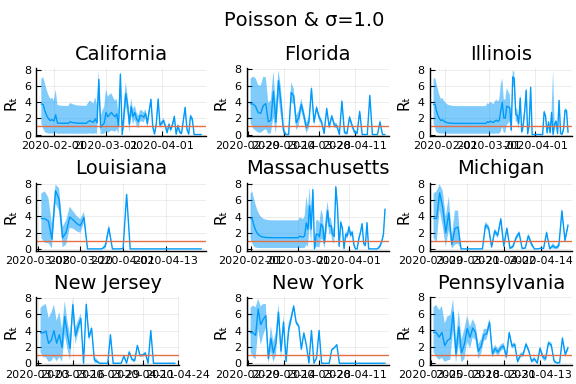
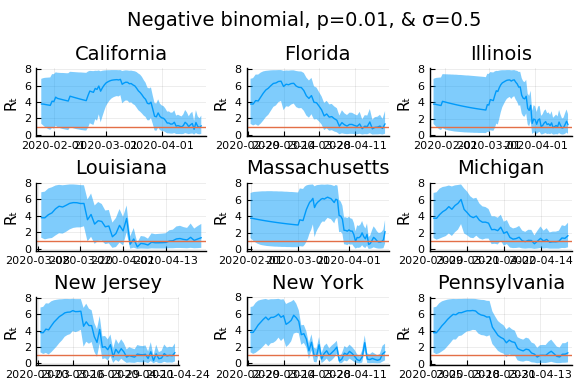
In these results, what is happening is that when new cases fluctuate too much, the likelihood is identically 0, causing the posterior calculation to break down. Increasing the variance of changes in $R_t$, widens the posterior confidence intervals, but does not solve the problem of vanishing likelihoods.
One thing that can “solve” the problem is choosing a distribution of $k_t | \lambda, k_{t-1}$ with higher variance. The negative binomial with parameters $\lambda p/(1-p)$ and $p$ has mean $\lambda$ and variance $\lambda/p$.
γ =1/7
σ = 0.25
Plots.closeall()
for σ in [0.1, 0.25, 0.5]
for nbp in [0.5, 0.1, 0.01]
figs = []
for gdf in groupby(sdf, :state)
p, m, cr = rtpost(gdf.newcases, γ, σ, x->pdf(truncated(Gamma(4,1),0,8), x),
(λ,x)->pdf(NegativeBinomial(λ*nbp/(1-nbp), nbp),x));
f = plot(gdf.date, m, ribbon=(m-cr[:,1], cr[:,2] - m), title=unique(gdf.state)[1], legend=:none, ylabel="Rₜ")
f = hline!(f,[1.0])
figs = vcat(figs, f)
end
l = @layout [a{.1h};grid(1,1)]
display(plot(plot(annotation=(0.5,0.5, "Negative binomial, p=$nbp, & σ=$σ"), framestyle = :none),
plot(figs[1:9]..., layout=(3,3)), layout=l, reuse=false))
end
end
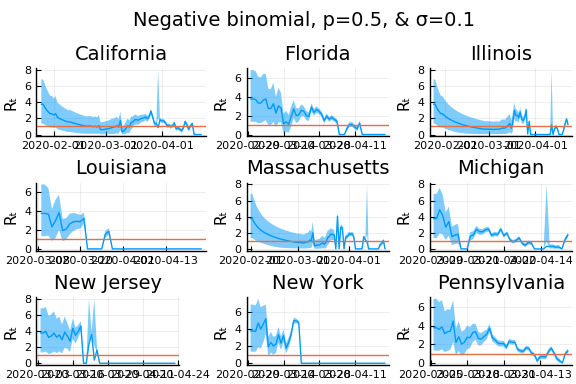
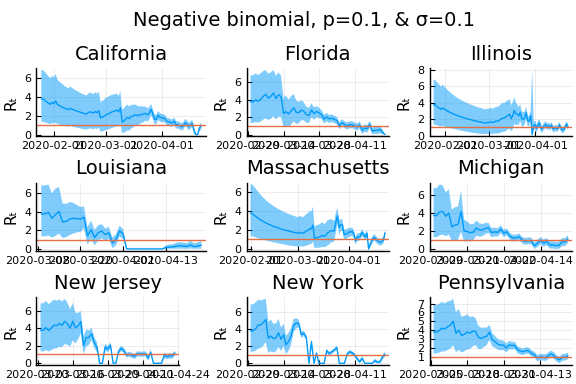
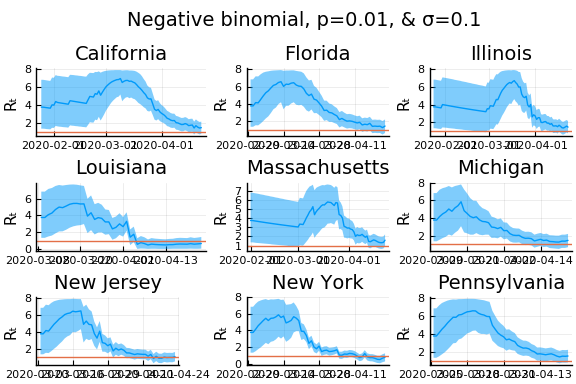
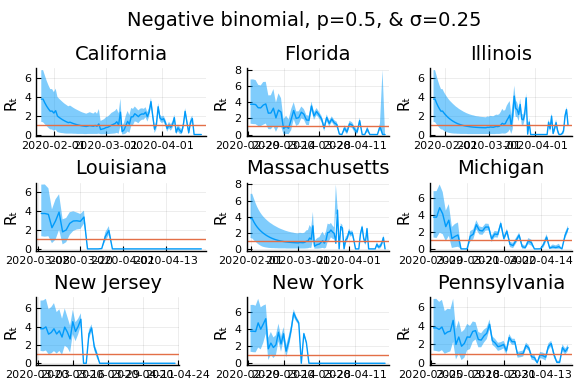
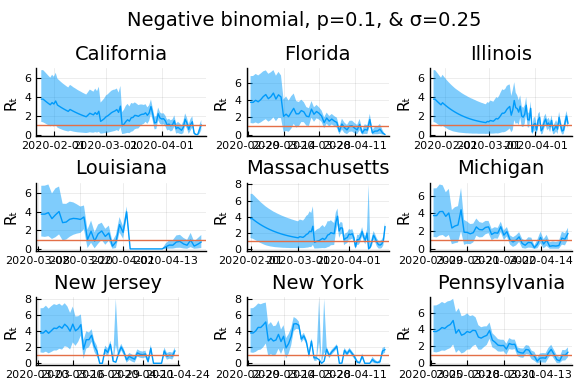
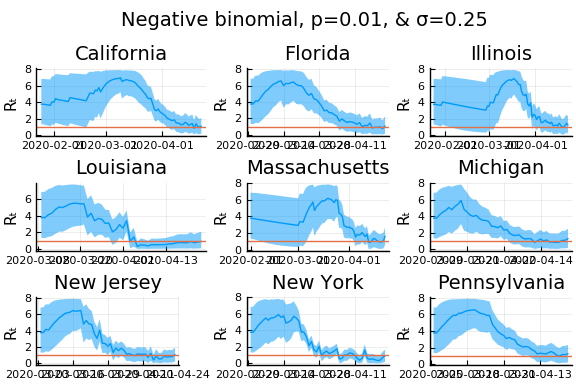
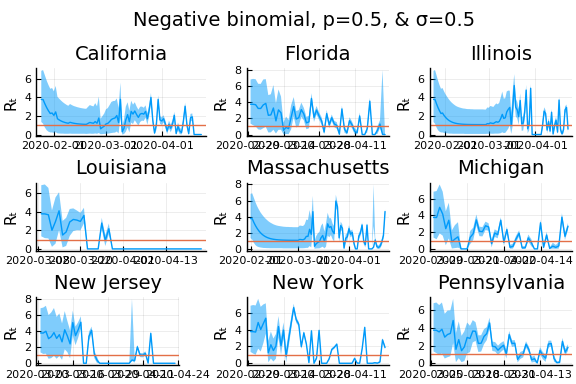
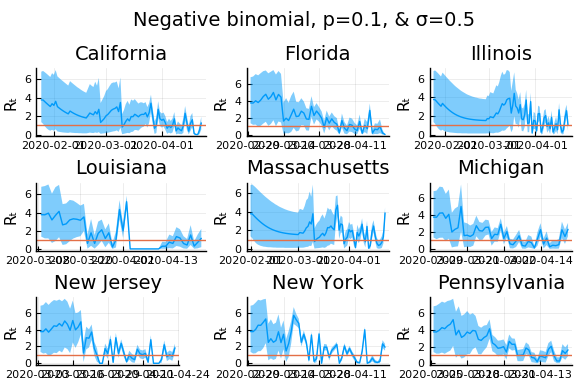
What Systrom did was smooth the new cases before using the Poisson distribution. He used a window width of $7$ and Gaussian weights with standard deviation $2$.
include("jmd/rtmod.jl")
σ = 0.25
Plots.closeall()
for w in [3, 7, 11]
for s in [0.5, 2, 4]
γ =1/7
nbp = 0.01
figs = []
for gdf in groupby(sdf, :state)
windowsize = w
weights = pdf(Normal(0, s), -floor(windowsize/2):floor(windowsize/2))
weights = weights/sum(weights)
smoothcases = RT.smoother(gdf.newcases, w=weights)
p, m, cr = rtpost(smoothcases, γ, σ, x->pdf(truncated(Gamma(4,1),0,8), x),
(λ,x)->pdf(Poisson(λ),x))
f = plot(gdf.date, m, ribbon=(m-cr[:,1], cr[:,2] - m), title=unique(gdf.state)[1], legend=:none, ylabel="Rₜ")
f = hline!(f,[1.0])
figs = vcat(figs, f)
end
l = @layout [a{.1h};grid(1,1)]
display(plot(plot(annotation=(0.5,0.5, "Poisson & σ=$σ, s=$s, w=$w"), framestyle = :none),
plot(figs[1:9]..., layout=(3,3)), layout=l, reuse=false))
end
end
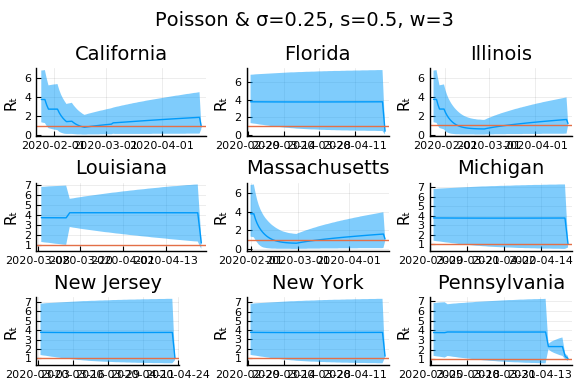
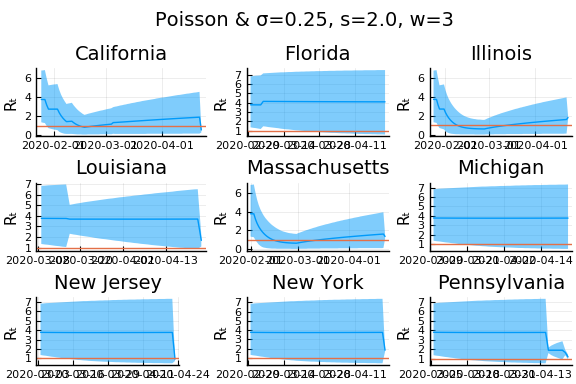
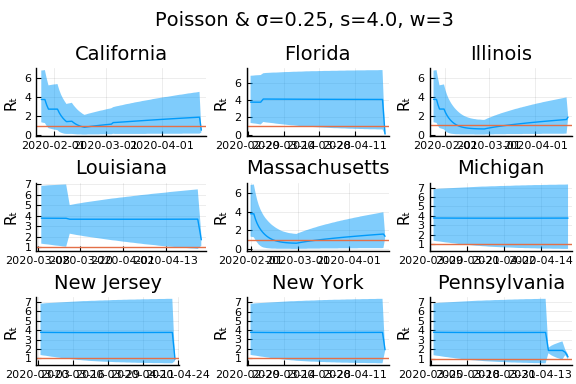
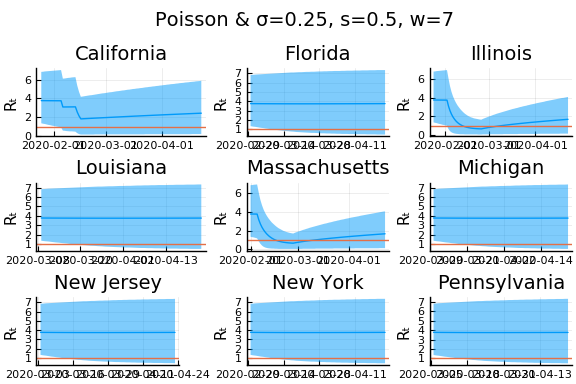
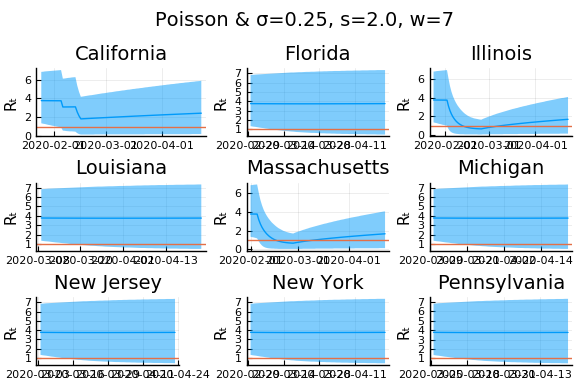
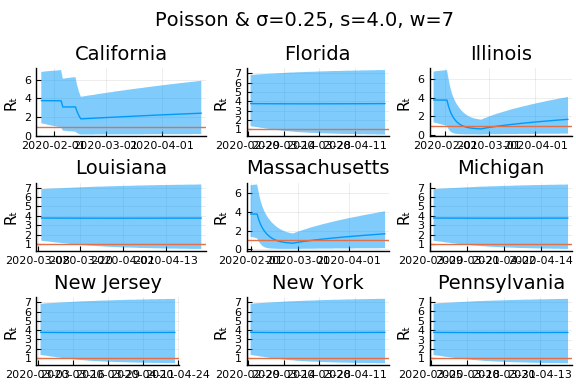
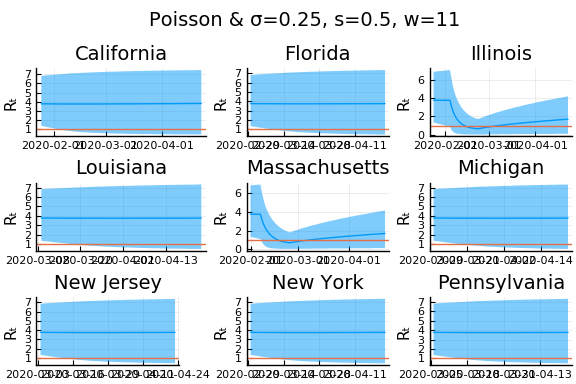
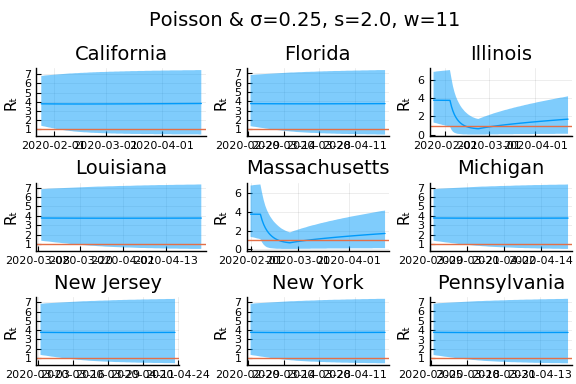
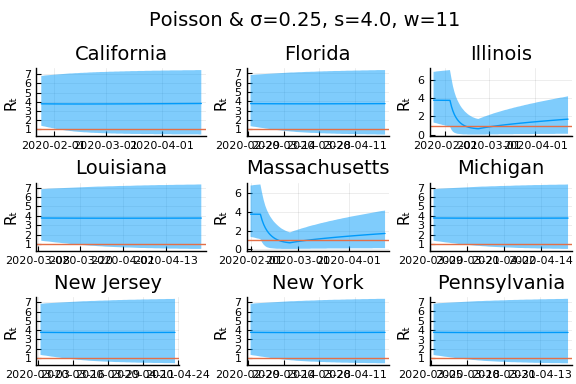
Here we see that we can get a variety of results depending on the smoothing used. All of these posteriors ignore the uncertainty in the choice of smoothing parameters (and procedure).
An alternative approach¶
Here we follow an approach similar in spirit to Systrom, with a few modifications and additions. The primary modification is that we alter the model of $k_t|k_{t-1}, R_t$ to allow measurement error in both $k_t$ and $k_{t-1}$. We make four additions. First, we utilize data on movement and business operations as auxillary noisy measures of $R_t$. Second, we allow state policies to shift the mean of $R_t$. Third, we combine data from all states to improve precision in each. Fourth, we incorporate testing numbers into the data.
As above, we begin from the approximation
where $k^*$ is the true, unobserved number of new cases. Taking logs and rearranging we have
Let $k_{s,t}$ be the noisy observed value of $k^*_{s,t}$, then
where and $\epsilon_{s,t}$ is measurement error.
With appropriate assumptions on $\epsilon$, $\tau$, $R$ and other observables, we can then use regression to estimate $R$.
As a simple example, let’s assume
- $R_{s,t} = R_{s,0} + \alpha d_{s,t}$ where $d_{s,t}$ are indicators for NPI’s being in place.
- That $\tau_{s,t}$ is constant over time for each $s$
- $E[\epsilon_{s,t} - \epsilon_{s,t-1}|d] = 0$ and $\epsilon_{s,t} - \epsilon_{s,t-1}$ is uncorrelated over time (just to simplify; this is not a good assumption).
```{=html}
``` julia
using GLM, RegressionTables
pvars = [Symbol("Stay.at.home..shelter.in.place"),
Symbol("State.of.emergency"),
Symbol("Date.closed.K.12.schools"),
Symbol("Closed.gyms"),
Symbol("Closed.movie.theaters"),
Symbol("Closed.day.cares"),
Symbol("Date.banned.visitors.to.nursing.homes"),
Symbol("Closed.non.essential.businesses"),
Symbol("Closed.restaurants.except.take.out")]
sdf = copy(df)
for p in pvars
sdf[!,p] = by(sdf, :state, (:date, p) => x->(!ismissing(unique(x[p])[1]) .& (x.date .>= unique(x[p])[1]))).x1
end
sdf = sort(sdf, [:state, :date])
sdf[!,:newcases] = by(sdf, :state, newcases = Symbol("cases.nyt") => x->(vcat(missing, diff(x))))[!,:newcases]
sdf[!,:dlogk] = by(sdf, :state, dlogk = :newcases => x->(vcat(missing, diff(log.(max.(x,0.1))))))[!,:dlogk]
fmla = FormulaTerm(Term(:dlogk), Tuple(Term.(vcat(pvars,:state))))
reg = lm(fmla, sdf)
regtable(reg, renderSettings=asciiOutput())
-----------------------------------------------
dlogk
-------
(1)
-----------------------------------------------
(Intercept) 0.185
(0.184)
Stay.at.home..shelter.in.place -0.057
(0.067)
State.of.emergency 0.037
(0.080)
Date.closed.K.12.schools -0.174*
(0.087)
Closed.gyms -0.086
(0.129)
Closed.movie.theaters 0.074
(0.136)
Closed.day.cares -0.012
(0.063)
Date.banned.visitors.to.nursing.homes 0.042
(0.052)
Closed.non.essential.businesses 0.040
(0.079)
Closed.restaurants.except.take.out -0.006
(0.114)
state: Alaska -0.032
(0.249)
state: Arizona -0.009
(0.214)
state: Arkansas 0.005
(0.247)
state: California -0.032
(0.214)
state: Colorado -0.014
(0.239)
state: Connecticut 0.051
(0.243)
state: Delaware -0.005
(0.247)
state: District of Columbia 0.065
(0.242)
state: Florida 0.078
(0.235)
state: Georgia 0.073
(0.236)
state: Hawaii -0.031
(0.240)
state: Idaho -0.058
(0.250)
state: Illinois -0.020
(0.213)
state: Indiana 0.062
(0.241)
state: Iowa -0.040
(0.243)
state: Kansas 0.071
(0.242)
state: Kentucky 0.046
(0.241)
state: Louisiana -0.012
(0.244)
state: Maine -0.021
(0.249)
state: Maryland 0.091
(0.239)
state: Massachusetts 0.011
(0.216)
state: Michigan 0.119
(0.246)
state: Minnesota 0.068
(0.241)
state: Mississippi 0.105
(0.247)
state: Missouri 0.091
(0.242)
state: Montana -0.055
(0.250)
state: Nebraska 0.039
(0.225)
state: Nevada 0.077
(0.239)
state: New Hampshire 0.007
(0.236)
state: New Jersey 0.106
(0.238)
state: New Mexico 0.042
(0.247)
state: New York 0.136
(0.235)
state: North Carolina 0.095
(0.237)
state: North Dakota 0.069
(0.247)
state: Ohio 0.135
(0.244)
state: Oklahoma 0.083
(0.240)
state: Oregon 0.038
(0.233)
state: Pennsylvania 0.072
(0.241)
state: Rhode Island 0.079
(0.235)
state: South Carolina 0.082
(0.241)
state: South Dakota 0.010
(0.246)
state: Tennessee 0.093
(0.239)
state: Texas -0.004
(0.222)
state: Utah 0.024
(0.231)
state: Vermont -0.027
(0.242)
state: Virginia 0.052
(0.242)
state: Washington -0.032
(0.212)
state: West Virginia 0.025
(0.257)
state: Wisconsin -0.008
(0.218)
state: Wyoming 0.003
(0.247)
-----------------------------------------------
Estimator OLS
-----------------------------------------------
N 2,621
R2 0.007
-----------------------------------------------
From this we get that if we assume $\gamma = 1/7$, then the the baseline estimate of $R$ in Illinois is $7(0.046 + 0.034) + 1\approx 1.56$ with a stay at home order, $R$ in Illinois becomes $7(0.046 + 0.035 - 0.147) + 1 \approx 0.53$.
Some of the policies have positive coefficient estimates, which is strange. This is likely due to assumption 1 being incorrect. There is likely an unobserved component of $R_{s,t}$ that is positively correlated with policy indicators.
State space model¶
A direct analog of Systrom’s approach is to treat $R_{s,t}$ as an unobserved latent process. Specifically, we will assume that
Note that the Poisson assumption on the distribution of $k_{s,t}$ used by Systrom implies an extremely small $\sigma^2_k$, since the variance of log Poisson($\lambda$) distribution is $1/\lambda$.
If $\epsilon_{s,t} - \epsilon_{s,t-1}$ weere independent over $t$, we could compute the likelihood and posteriors of $R_{s,t}$ through the standard Kalman filter. Of course, $\epsilon_{s,t} - \epsilon_{s,t-1}$ is not independent over time, so we must adjust the Kalman filter accordingly. We follow the approach of (Kurtz and Lin 2019) to make this adjustment.
Question
Is there a better reference? I’m sure someone did this much earlier than 2019…
We estimate the parameters using data from US states. We set time 0 as the first day in which a state had at least 10 cumulative cases. We then compute posteriors for the parameters by MCMC. We place the following priors on the parameters.
using Distributions, TransformVariables, DynamicHMC, MCMCChains, Plots, StatsPlots,
LogDensityProblems, Random, LinearAlgebra, JLD2
include("jmd/rtmod.jl")
rlo=-1
rhi=1.1
priors = (γ = truncated(Normal(1/7,1/7), 1/28, 1/1),
σR0 = truncated(Normal(1, 3), 0, Inf),
α0 = MvNormal([1], 3),
σR = truncated(Normal(0.25,1),0,Inf),
σk = truncated(Normal(0.1, 5), 0, Inf),
α = MvNormal([1], 3),
ρ = Uniform(rlo, rhi))
(γ = Truncated(Normal{Float64}(μ=0.14285714285714285, σ=0.14285714285714285
), range=(0.03571428571428571, 1.0)), σR0 = Truncated(Normal{Float64}(μ=1.0
, σ=3.0), range=(0.0, Inf)), α0 = IsoNormal(
dim: 1
μ: [1.0]
Σ: [9.0]
)
, σR = Truncated(Normal{Float64}(μ=0.25, σ=1.0), range=(0.0, Inf)), σk = Tr
uncated(Normal{Float64}(μ=0.1, σ=5.0), range=(0.0, Inf)), α = IsoNormal(
dim: 1
μ: [1.0]
Σ: [9.0]
)
, ρ = Uniform{Float64}(a=-1.0, b=1.1))
The estimation is fast and the chain appears to mix well.
reestimate=false
sdf = sort(sdf, (:state, :date));
dlogk = [filter(x->((x.state==st) .&
(x.cases .>=10)),
sdf).dlogk for st in unique(sdf.state)];
dates = [filter(x->((x.state==st) .&
(x.cases .>=10)),
sdf).date for st in unique(sdf.state)];
mdl = RT.RtRW(dlogk, priors)
trans = as( (γ = asℝ₊, σR0 = asℝ₊, α0 = as(Array, 1),
σR = asℝ₊, σk = asℝ₊, α = as(Array,1),
ρ=as(Real, rlo, rhi)) )
P = TransformedLogDensity(trans, mdl)
∇P = ADgradient(:ForwardDiff, P)
p0 = (γ = 1/7, σR0=1.0, α0=[4.0],σR=0.25, σk=2.0, α=[1], ρ=0.9)
x0 = inverse(trans,p0)
@time LogDensityProblems.logdensity_and_gradient(∇P, x0);
1.901263 seconds (3.89 M allocations: 190.595 MiB)
rng = MersenneTwister()
steps = 100
warmup=default_warmup_stages(local_optimization=nothing,
stepsize_search=nothing,
init_steps=steps, middle_steps=steps,
terminating_steps=2*steps, doubling_stages=3, M=Symmetric)
x0 = x0
if (!isfile("rt1.jld2") || reestimate)
res = DynamicHMC.mcmc_keep_warmup(rng, ∇P, 2000;initialization = (q = x0, ϵ=0.1),
reporter = LogProgressReport(nothing, 25, 15),
warmup_stages =warmup);
post = transform.(trans,res.inference.chain)
@save "rt1.jld2" post
end
@load "rt1.jld2" post
p = post[1]
vals = hcat([vcat([length(v)==1 ? v : vec(v) for v in values(p)]...) for p in post]...)'
vals = reshape(vals, size(vals)..., 1)
names = vcat([length(p[s])==1 ? String(s) : String.(s).*"[".*string.(1:length(p[s])).*"]" for s in keys(p)]...)
cc = MCMCChains.Chains(vals, names)
display(cc)
Object of type Chains, with data of type 2000×7×1 reshape(::Adjoint{Float64
,Array{Float64,2}}, 2000, 7, 1) with eltype Float64
Iterations = 1:2000
Thinning interval = 1
Chains = 1
Samples per chain = 2000
parameters = γ, σR0, α0, σR, σk, α, ρ
2-element Array{ChainDataFrame,1}
Summary Statistics
parameters mean std naive_se mcse ess r_hat
────────── ────── ────── ──────── ────── ───────── ──────
γ 0.0931 0.0381 0.0009 0.0023 194.3582 1.0034
σR0 1.1247 0.7666 0.0171 0.0361 515.4800 1.0000
α0 5.0630 1.8530 0.0414 0.0870 344.8905 1.0025
σR 0.0957 0.0855 0.0019 0.0022 1213.6056 0.9996
σk 0.5685 0.0087 0.0002 0.0002 2659.9467 0.9999
α 0.6724 0.4373 0.0098 0.0181 498.8290 1.0004
ρ 0.9337 0.0144 0.0003 0.0005 672.3568 0.9997
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
────────── ─────── ────── ────── ────── ──────
γ 0.0438 0.0648 0.0828 0.1129 0.1883
σR0 0.0525 0.5365 0.9818 1.5750 2.8887
α0 2.2124 3.6443 4.8462 6.2334 9.1984
σR 0.0030 0.0336 0.0725 0.1313 0.3281
σk 0.5519 0.5626 0.5684 0.5744 0.5861
α -0.4498 0.4618 0.7480 0.9520 1.3733
ρ 0.9037 0.9249 0.9350 0.9435 0.9598
display(plot(cc))
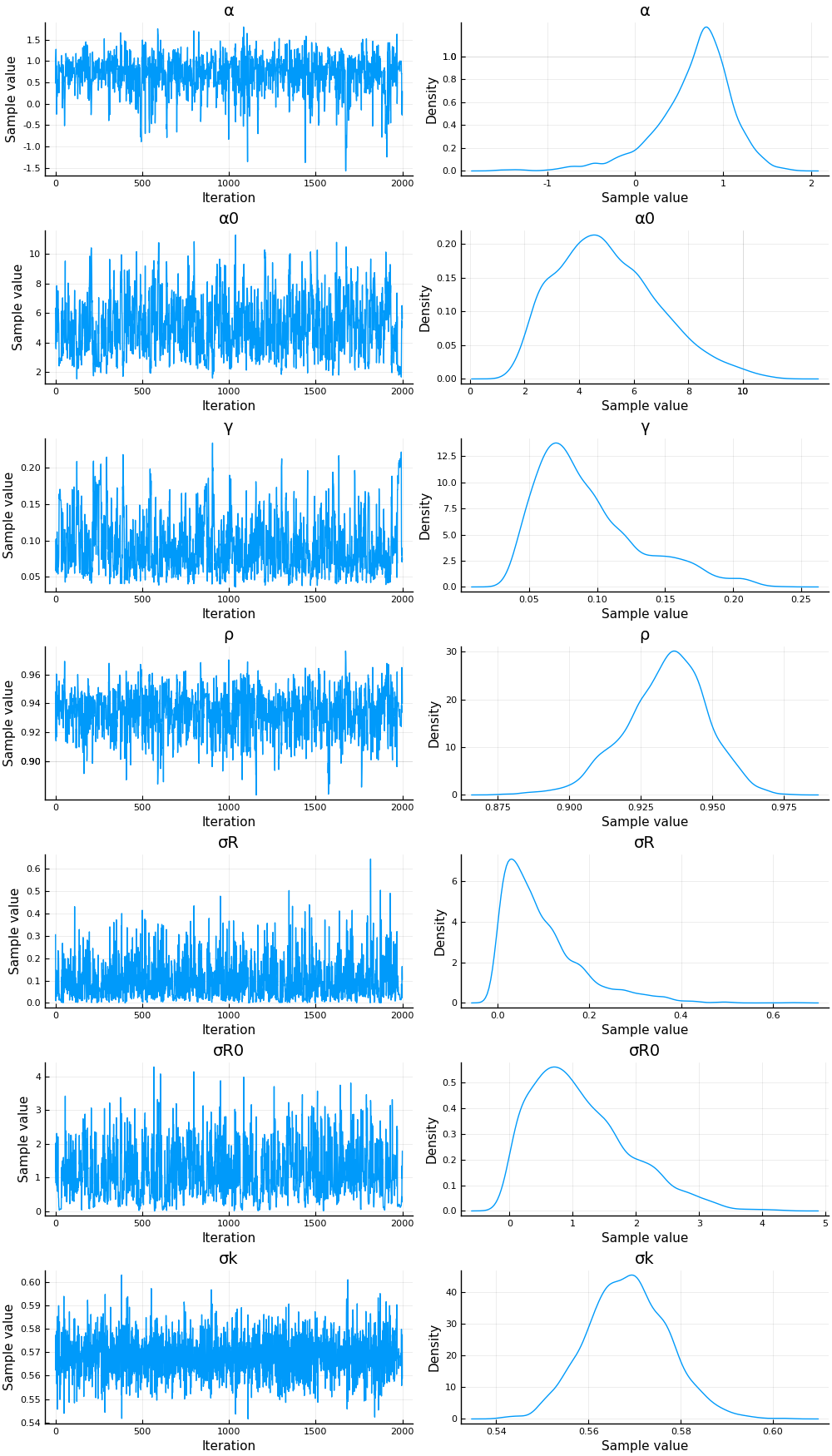
The posterior for the initial distribution of $R_{0,s}$ is not very precise. The other parameters have fairly precise posteriors. Systrom fixed all these parameters, except $\sigma_R$, which he estimated by maximum likelihood to be 0.25. In these posteriors, a 95% credible region for $\sigma_R$ contains his estimate. The posterior of $\rho$ is not far from his imposed value of $1$, although $1$ is out of the 95% credible region. A 95% posterior region for $\gamma$ contains Systrom’s calibrated value of $1/7$.
It is worth noting that the estimate of $\sigma_k$ is large compared to $\sigma_r$. This will cause new observations of $\Delta \log k$ will have a small effect on the posterior mean of $R$.
Given values of the parameters, we can compute state and time specific posterior estimates of $R_{s,t}$.
states = unique(sdf.state)
s = findfirst(states.=="New York")
figr = RT.plotpostr(dates[s],dlogk[s],post, ones(length(dlogk[s]),1), [1])
display(plot(figr, ylim=(-1,10)))
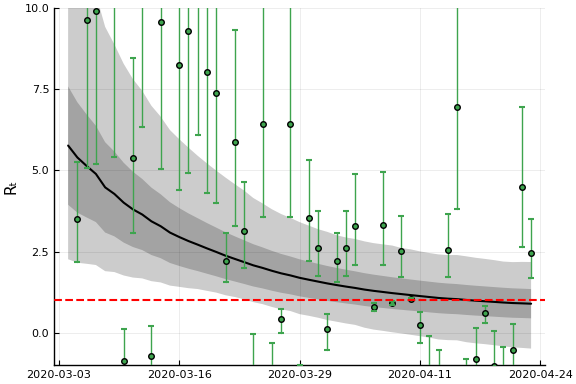
This figure shows the posterior distribution of $R_{s,t}$ in New York. The black line is the posterior mean. The dark grey region is the average (over model parameters) of a 90% credible region conditional on the model parameters. This is comparable to what Systrom (and many others) report, and ignores uncertainty in the model parameters. The light grey region is a 90% credile region taking into account parameter uncertainty. The points and error bars are mean and 90% credible regions for
Posteriors for additional states¶
states_to_plot = ["New Jersey","Massachusetts","California",
"Georgia","Illinois","Michigan",
"Ohio","Wisconsin","Washington"]
S = length(states_to_plot)
figs = fill(plot(), 9*(S ÷ 9 + 1))
for (i,st) in enumerate(states_to_plot)
s = findfirst(states.==st)
figr = RT.plotpostr(dates[s],dlogk[s],post, ones(length(dlogk[s]),1),[1])
l = @layout [a{.1h}; grid(1,1)]
figs[i] = plot(plot(annotation=(0.5,0.5, st), framestyle = :none),
plot(figr, ylim=(-1,10)), layout=l)
if ((i % 9) ==0 || ( i==length(states_to_plot)))
display(plot(figs[(i-8):i]..., layout=(3,3), reuse=false))
end
end
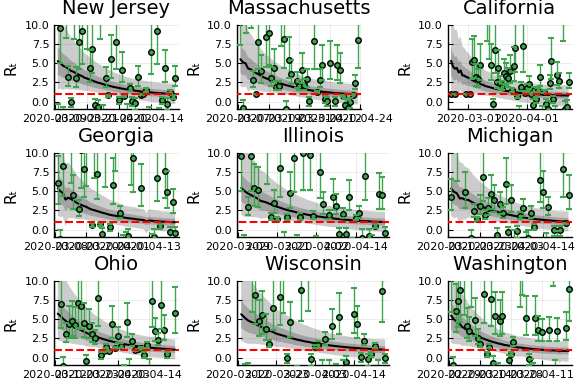
We can see that the posteriors vary very little from state to state. The model picks up a general downward trend in $\Delta \log k$ through the slightly less than 1 estimate of $\rho$. This drives the posteriors of $R_{s,t}$ in every state to decrease over time. Since $\sigma_k >> \sigma_R$, the actual realizations of $\Delta \log k$ do not affect the state-specific posteriors very much.
Note
I also tried fixing $\rho=1$. This gives similar results in terms of $\sigma_k >> \sigma_R$, and gives a posterior for $R_{s,t}$ that is approximately constant over time.
Bettencourt, Ruy M., Luís M. A. AND Ribeiro. 2008. “Real Time Bayesian Estimation of the Epidemic Potential of Emerging Infectious Diseases.” PLOS ONE 3 (5): 1–9. https://doi.org/10.1371/journal.pone.0002185.
Kurtz, Vince, and Hai Lin. 2019. “Kalman Filtering with Gaussian Processes Measurement Noise.”